Контент-анализ (от англ. "содержание" и греч. "разложение, расчленение") - метод выявления и оценки характеристик информации, содержащихся в текстах и речевых сообщениях. Предусматривает строгую формализацию процессов осмысления материала.
Включает в себя:
- выделение системы опорных понятий (категорий анализа);
- отыскание их индикаторов - слов, словосочетаний, суждений и т. п. - (единиц анализа);
- статистическую обработку данных.
Данный метод зародился в 20-е гг. в американской журналистике как средство количественно-качественного изучения содержания прессы. В настоящее время активно применяется в социальной психологии, социологии, психодиагностике, политологии, психологии рекламы и пропаганды.
К числу его несомненных достоинств относятся возможность точной регистрации внешне неразличимых показателей в объемных массивах эмпирических данных, способность к выявлению скрытых тенденций и закономерностей, допустимость осуществления отсроченного по времени анализа событий и ситуаций, относительная объективность процедур и надёжность результатов, отсутствие проявлений эффекта воздействия исследователя на поведение испытуемых.
По сути, контент-анализ предполагает перевод качественно представленной информации на язык счета. Для этого необходимо, во-первых, иметь достаточно объемный и содержательно богатый текст, а во-вторых, обладать определенным уровнем исследовательской подготовленности, позволяющим эффективно реализовать потенциал данного метода.
Наряду с этим следует помнить, что контент-анализу присущи и некоторые ограничения. Так, известно, что характер информации во многом определяется замыслами ее автора и спецификой форм предъявления. Поэтому вполне возможно принятие исследователем вымысла за документальность или упущение каких-либо существенных данных вследствие недостаточной выраженности их в обрабатываемом материале. Искажения информации могут возникать и но вине исследователя, неспособного, к примеру, адекватно выделить категории анализа или учесть вес имеющиеся варианты их словесного выражения.
Кроме того, далеко не всякий материал поддастся необходимой формализации. Предельно трудно было бы применить данный метод, скажем, к описанию поведения лирического героя поэтического произведения.
В современной психологической практике контент-анализ находит свое применение в трех разновидностях:
1) в качестве основного метода исследований;
2) как составная часть используемого комплекса исследовательских методов;
3) в виде вспомогательной процедуры обработки данных, полученных иными эмпирическими способами.
В любом случае, представляется необходимой предварительная проверка достоверности анализируемого текста или устного сообщения, а также установление степени надежности, содержательной и критериальной валидности аналитической процедуры. Иначе обоснованность и объективность результатов могут оказаться неудовлетворительными.
Описывая особенности применения контент-анализа, принято указывать меру устойчивости полученных сведений при замене кодировщиков (лиц, регистрирующих предписанные параметры и признаки) и давать характеристику степени согласованности результатов этого метода с данными, собранными другими способами.
Рассмотрим содержание основных этапов контент-анализа.
1. Подготовительный этап (разработка программы анализа материала). Он включает постановку цели исследования, предварительную проверку адекватности избранного метода особенностям предстоящей работы, составление классификатора (опорной схемы для контент-анализа), подготовку инструкций для лиц, участвующих в реализации метода, пилотажное исследование, последующую коррекцию программы.
Особое внимание следует здесь обратить на составление т. н. классификатора, представляющего собой перечень категорий анализа, соответствующих им индикаторов, принятых единиц счета. Это основа алгоритма последующих действий, от качества которой зависит эффективность работы в целом.
Категории анализа - это ключевые элементы исследовательской концепции, смысловые единицы, выраженность которых подлежит регистрации в соответствии с поставленной цел МО. В качестве категорий анализа исследователь заранее выдвигает определенные проблемы, идеи или темы.
Например, анализируя характер человека по итогам интервью или анкетирования, мы можем выделить следующие категории: отношение его к самому себе, другим людям, деятельности, вещам (предметам), природе. Изучая, допустим, тревожность как свойство личности, мы предварительно выделяем совокупность составляющих ее "тем": беспокойство но поводу здоровья, семьи, карьеры, финансового положения и др.
Главное, чтобы список категорий был предельно исчерпывающим, а также давал возможность однозначного соотнесения той или иной части текста с конкретной категорией.
Единицы анализа, или индикаторы, признаки выраженности смысловых единиц, представляют собой части текста, характеризующиеся принадлежностью к определенной категории. Это могут быть символы, слова, термины, сочетания слов различной протяженности, ситуации, суждения, реплики, интонации и т. д. Это ют материал, который позволяет судить о значении в тексте каждой категории.
Следует помнить, что одна и та же категория бывает выражена в тексте по-разному: от отдельных символов или слоя до законченных суждений или абзацев. Поэтому выделение единиц анализа является непростым делом и требует от исследователя вдумчивости и проницательности.
Помимо этого необходимо учитывать, что категория может быть представлена в тексте различными но знаку единицами анализа. Например, в отрицательной (критической), нейтральной или же положительной форме. Разумеется, варианты такого рода отношений бывает и более разнообразными.
Единицы счета - это количественные характеристики отношений категорий друг к другу или единиц анализа к категориям.
В практике исследований обычно используют два их варианта:
- частоту проявлений в тексте категории или се признака;
- пропорцию представленности категории (сё признака) или, иначе, объём внимания, уделяемый ей автором текста. Так, это может быть: сравнительное количество печатных знаков, площадь соответствующих частей текстов (в квадратных единицах или процентах), необходимое время произнесения и т. д.
Разработка классификатора завершается составлением инструкций кодировщику и подготовкой кодировочной матрицы.
Инструкции содержат предельно четкие указания на то, каковы все выделенные категории, какой набор признаков в тексте соответствует каждой из них. какого типа единицы счета при этом используются. Объективность результатов контент-анализа будет более полной, если исследователь письменно сформулирует инструкции даже в том случае, когда он сам является кодировщиком.
Кодировочная матрица представляет собой таблицу, удобную для регистрации первичных результатов исследования. Обычно по вертикали в ней даны категории анализа, а по горизонтали - перечень источников информации (отдельные документы, сообщения, персоналии испытуемых и т. п.). Тогда середина таблицы заполняется цифрами, свидетельствующими о частотах присутствия данной категории в том или ином материале.
Пилотажное исследование, завершающее подготовительный этан контент-анализа, способствует выявлению недостающих категорий, упущенных из виду единиц анализа, неточностей инструкций.
2. Исполнительный этап предусматривает совокупность процедур по выделению индикаторов категорий и регистрации характеристик их присутствия в тексте.
Кодировщики могут допускать здесь такие ошибки, как:
- неверное соотнесение единиц анализа с категориями;
- пропуск тех или иных единиц анализа;
- фиксация того, чего нет на самом деле.
Все это нарушает устойчивость результатов контент-анализа. Причины низких показателей устойчивости следует искать в качестве инструкций, недостаточной умелости кодировщиков, в неподходящей обстановке их работы, наконец, в отсутствии внимательности, терпения или добросовестности.
3. Этап обработки данных. Содержание его определяется целью исследования. В зависимости от этого при обработке результатов (одной или нескольких кодировочных матриц) могут быть использованы частотные или процентные распределения, коэффициенты корреляции, сопоставительные таблицы и т. д.
В тех случаях, когда анализируется большой массив данных, иногда используются специальные математико-статистические способы, разработанные для нужд контент-анализа.
В качестве примера укажем на метод Чарльза Осгуда, направленный на выявление случайных и неслучайных зависимостей элементов содержания. Суть его заключается в следующем: вначале рассчитывается величина ожидаемой вероятности совместной встречаемости двух единиц анализа, а затем этот показатель сравнивается с выявленной при контент-анализе величиной фактической встречаемости этих единиц.
Например, единица X встречается в 20% анализируемых текстов (Рх = 0,2), а единица Y - в 30 % (Р = 0,3). Тогда можно ожидать, что совместно эти единицы проявятся с вероятностью 0,06 (в соответствии с формулой Рх = Р Р). На деле же оказывается, что совместно они были зарегистрированы лишь в 2% случаев (Фху = 0,02). Очевидно, что фактическая зависимость данных единиц анализа случайна.
Однажды Ч. Осгуд, проанализировав монологи популярного американского радиокомментатора, выявил наличие неожиданной ассоциативной взаимосвязи таких понятий, как "молодежь" и "болезненные проявления", а также общую сугубо консервативную тенденциозность его бесед в эфире.
Или другой пример - расчет коэффициента Яниса, при помощи которого может быть установлено соотношение положительных и отрицательных оценок относительно определенных категорий.
Данный коэффициент исчисляется по формуле:

где f - число положительных оценок, п - число отрицательных оценок,
r - объем единиц информации, отражающих изучаемую категорию,
t — общий объём единиц анализируемого текста.
В последние десятилетия все чаще при обработке данных контент-анализа или корреляционного анализа используется особый метод математической статистики, позволяющий выявить скрытые от непосредственного восприятия признаки (факторы), а также уточнить степень их влияния на тс или иные рассматриваемые характеристики.
Факторный анализ применяется, когда возникает необходимость определить совокупность вероятных причинно-следственных связей между переменными, установить наличие феноменов, объясняющих существование взаимосвязей.
Предположим, что, исследуя проблему зависимости успеваемости школьников от их психологических характеристик, мы получили значения парных взаимных корреляций между успеваемостью, потребностями и способностями. Для понимания сути факторного анализа воспользуемся наглядной моделью , в которой каждому из названных параметров соответствует отдельный прямоугольник. При этом площади пересечений фигур символически изображают величины коэффициентов корреляции.
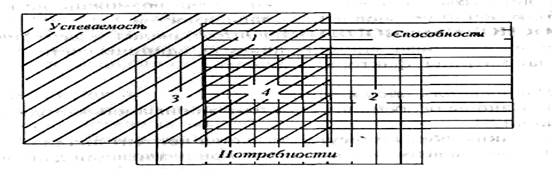
Таким образом, в зоне 1 находятся общие признаки проявлений способностей и успеваемости, в зоне 2 - способностей и потребностей, в зоне 3 - успеваемости и потребностей. Наконец, в зоне 4 присутствуют признаки, объединенные неким общим фактором для успеваемости, потребностей и способностей.
Разумеется, это только иллюстративная схема. Техники факторного анализа изучаются в пределах курса математической статистики. Наша задача - сформировать первоначальное представление об этом весьма перспективном методе обработки данных.
Основные идеи факторного анализа были предложены Чарльзом Спирменом (1904), рассматривавшим его как средство изучения интеллекта. По Спирмену, существует основной, или генеральный фактор, обеспечивающий успех в любой интеллектуальной деятельности (фактор G) и множество частных, специфических (факторы S), связанных с отдельными, конкретными сферами интеллектуальных занятий.
Дальнейшее развитие техники факторного анализа связано с именем Луиса Терстоуна, обосновавшего наличие групповых факторов, проявляющихся в комплексе интеллектуальных занятий, но не имеющих генерального значения. Его концепция многофакторного анализа (1931) считается потенциально более информативной.
Следует иметь в виду, что факторный анализ имеет и определенные слабые стороны. В частности, отсутствует однозначное математическое решение проблемы факторных нагрузок, т. с. влияния отдельных факторов на изменения тех или иных переменных. Кроме того, как бы точно не был проведен сам анализ, психологическая интерпретация сто результатов сохраняет субъективность. Почти всегда возможны несколько истолкований установленных зависимостей.
Поможем написать любую работу на аналогичную тему