Описание этого критерия дается с использованием руководства J.Greene, M.D'Olivera (1982). Он описан также у М. Холлендера, ДА. Вулфа (1983).
Назначение критерия S
Критерий S предназначен для выявления тенденций изменения признака при переходе от выборки к выборке при сопоставлении трех и более выборок.
Описание критерия S
Критерий S позволяет нам упорядочить обследованные выборки по какому-либо признаку, например, по креативности, фрустрацноннон толерантности, гибкости и т.п.
Мы сможем утверждать, что на первом месте по выраженности исследуемого признака стоит выборка, скажем, Б, на втором - А, на третьем - В и т.д. Интерпретация полученных результатов будет зависеть от того, по какому принципу были образованы исследуемые выборки. Здесь возможны два принципиально отличных варианта.
1) Если обследованы выборки, различающиеся по качественным признакам (профессии, национальности, месту работы и т. п.), то с помощью критерия S мы сможем упорядочить выборки по количественно измеряемому признаку (креативности, фрустрационной толерантности, гибкости и т.п.).
2) Если обследованы выборки, различающиеся или специально сгруппированные по количественному признаку (возрасту, стажу работы, социометрическому статусу и др.), то, упорядочивая их теперь уже по другому количественному признаку, мы фактически устанавливаем меру связи между двумя количественными признаками. Например, мы можем показать с помощью критерия S, что при переходе от младшей возрастной группы к старшей фрустрационная толерантность возрастает, а гибкость, наоборот, снижается.
Меру связи между количественно измеренными переменными можно установить с помощью вычисления коэффициента ранговой корреляции или линейной корреляции. Однако критерий тенденции S имеет следующие преимущества перед коэффициентами корреляции:
а) критерий тенденций S более прост в подсчете;
б) он применим и в тех случаях, когда один из признаков варьирует в узком диапазоне, например, принимает всего 3 или 4 значения, в то время как при подсчете ранговой корреляции в этом случае мы получаем огрубленный результат, нуждающийся в поправке на одинаковые ранги.
Критерий S основан на способе расчета, близком к принципу критерия Q Розенбаума. Все выборки располагаются в порядке возрастания исследуемого признака, при этом выборку, в которой значения в общем ниже, мы помещаем слева, выборку, в которой значения выше, правее, и так далее в порядке возрастания значений. Таким образом, все выборки выстраиваются слева направо в порядке возрастания значений исследуемого признака.
При упорядочивании выборок мы можем опираться на средние значения в каждой выборке или даже на суммы всех значений в каждой выборке, потому что в каждой выборке должно быть одинаковое количество значений. В противном случае критерий S неприменим (подробнее об этом см. в разделе "Ограничения критерия S").
Для каждого индивидуального значения подсчитпывается количество значений справа, превышающих его по величине. Если тенденция возрастания признака слева направо существенна, то большая часть значений справа должна быть выше. Критерий S позволяет определить, преобладают ли справа более высокие значения или нет. Статистика S отражает степень этого преобладания. Чем выше эмпирическое значение S, тем тенденция возрастания признака является более существенной.
Следовательно, если Sэмп равняется критическому значению или превышает его, нулевая гипотеза может быть отвергнута.
Гипотезы
H0: Тенденция возрастания значений признака при переходе от выборки к выборке является случайной.
H1: Тенденция возрастания значений признака при переходе от выборки к выборке не является случайной.
Графическое представление критерия
Фактически критерий S позволяет определить, достаточно ли велика суммарная зона неперекрещивающихся значений в сопоставляемых выборках: действительно ли в первом ряду значения в общем ниже, чем в последующих, во втором - ниже, чем в оставшихся справа последующих и т. д.
Графически это представлено на Рис. 2.7.
На Рис. 2.7(а) у сопоставляемых рядов значений есть непере-крещивающиеся зоны, но их суммарная площадь может оказаться слишком небольшой, чтобы признать тенденцию возрастания признака существенной.
На рис. 2.7(6) сумма неперекрещивающихся зон, по-видимому, достаточно велика, чтобы тенденция возрастания признака была признана достоверной. Точно определить это мы сможем лишь с помощью критерия S.
![]()
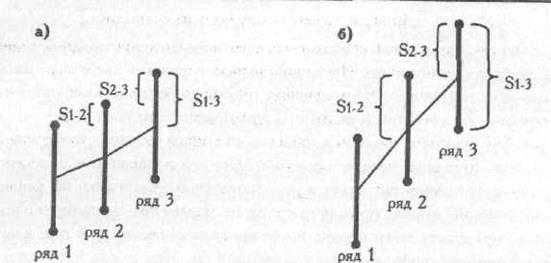
Рис. 2.1. Варианты соотношения 3-х рядов значений: S1-2 - зона тех значений 2-го ряда, которые выше всех значений 1-го ряда; S1-3 - зона тех значений 3-го ряда, которые выше всех значений 1-го ряда; S2-3 - зона тех значений 3-го рада, которые выше всех значений 2-го ряда
Ограничения критерия S
1. В каждой из сопоставляемых выборок должно быть одинаковое число наблюдений. Если число наблюдений неодинаково, то придется искусственно уравнивать выборки, утрачивая при этом часть полученных наблюдений.
Например, если в двух выборках по 7 наблюдений, а в третьей - 11, то 4 из них необходимо отсеять. Для этого карточки с индивидуальными значениями переворачиваются лицевой стороной вниз и перемешиваются, а затем из них случайным образом извлекается 7 карточек. Оставшиеся 4 карточки с индивидуальными значениями не включаются в дальнейшее рассмотрение и в подсчет критерия S. Ясно, что при таком подходе часть информации утрачивается, и общая картина может быть искажена.
Если исследователь хочет избежать этого, ему следует воспользоваться критерием Н, позволяющим выявить различия между тремя и более выборками без указания на направление этих различий (см. вопрос 4).
2. Нижний порог: не менее 3 выборок и не менее 2 наблюдений в каждой выборке. Верхний порог в существующих таблицах: не более 6 выборок и не более 10 наблюдений в каждой выборке (см. Табл. III Приложения 1 для определения критических значений S). При большем количестве выборок или наблюдений в них придется пользоваться критерием Н Крускала-Уоллиса.
Пример
Выборка претендентов на должность коммерческого директора в Санкт-Петербургском филиале зарубежной фирмы была обследована с помощью Оксфордской методики экспресс-видеодиагностики, использующей диагностические ролевые игры. Были обследованы 20 мужчин в возрасте от 25 до 40 лет, средний возраст 31,5 года. Оценки производились по 15 значимым, с точки зрения зарубежной фирмы, психологическим качествам, обеспечивающим эффективную деятельность на посту коммерческого директора. Одним из этих качеств была "Авторитетность". В конце 8-часового сеанса диагностических ролевых игр и упражнений проводился социометрический опрос участников группы, в котором они должны были ответить на вопрос: "Если бы я сам был представителем фирмы, я выбрал бы на должность коммерческого директора: 1).... 2).... 3)...." Участники знали, что каждый их шаг является материалом для диагностики, и что в данном случае, в частности, проверяется, помимо прочего, их способность к объективному суждению о людях. В результате этой процедуры каждый участник получил то или иное количество выборов от других участников, отражающее его социометрический статус в группе претендентов.
Результаты исследования представлены в Табл. 2.7 (данные Е. В. Сидоренко, И. В. Дермановой, 1991).
Можно ли считать, что группы с разным статусом различаются и по уровню авторитетности, определявшейся независимо от социометрии с помощью экспресс-видеодиагностики?
Таблица 2.7
Показатели по шкале Авторитетности в группах с разным социометрическим статусом (N=20)
|
Номера испытуемых |
Группа 1 0 выборов (n1=5) |
Группа 2 1 выбор (n2=5) |
Группа 3 2-3 выбора (n3=5) |
Группа 4 4 и более выборов (n4=5) |
|
1 |
5 |
5 |
5 |
9 |
|
2 |
5 |
6 |
6 |
9 |
|
3 |
2 |
7 |
7 |
8 |
|
4 |
5 |
6 |
7 |
8 |
|
5 |
4 |
4 |
5 |
7 |
|
Суммы |
21 |
28 |
30 |
41 |
|
Средние |
4,2 |
5,6 |
6,0 |
8,2 |
Сформулируем гипотезы.
H0: Тенденция повышения значений по шкале Авторитетности при переходе от группы к группе (слева направо) случайна.
H1: Тенденция повышения значений по шкале Авторитетности при переходе от группы к группе (слева направо) неслучайна.
Для того, чтобы нам было удобнее подсчитывать количества более высоких значении (S;), лучше упорядочить значения в каждой группе по их возрастанию (Табл. 2.8).
Таблица 2.8
Расчет критерия S при сопоставлении групп с разным социометрическим статусом по показателю Авторитетности (N=20)
|
Места испыту-емых |
Группа 1 0 выборов (n1=5) |
Группа 2 1 выбор (n2=5) |
Группа 3 2-3 выборf (n3=5) |
Группа 4 4 и более выборов (n4=5) |
|||
|
|
Индиви-дуальные значения |
Si |
Индиви-дуальные значения |
Si |
Индиви-дуальные значения |
Si |
Индиви-дуальные значения |
|
1 |
2 |
(15) |
4 |
(10) |
5 |
(5) |
7 |
|
2 |
4 |
(14) |
5 |
(8) |
5 |
(5) |
8 |
|
3 |
5 |
(11) |
6 |
(7) |
6 |
(5) |
8 |
|
4 |
5 |
(11) |
6 |
(7) |
7 |
(4) |
9 |
|
5 |
5 |
(11) |
7 |
(4) |
7 |
(4) |
9 |
|
Суммы |
(62) |
(36) |
(23) |
||||
После того, как все индивидуальные значения расположены в порядке возрастания, легко подсчитать, сколько значений справа превышают данное значение слева. Начнем с крайнего левого столбца. Значение "2" превышают все 15 значений из трех правых столбцов; значение "4" - 14 значений из трех правых столбцов; значение "5" превышают 11 значений из трех правых столбцов. Полученные количества "превышений" запишем в скобках слева от каждого индивидуального значения, как это сделано в Табл. 2.8.
Расчет для второго столбца производим по тому же принципу. Мы видим, что значение "4" превышают все 10 значений из оставшихся столбцов справа; значение "5" - 8 значений из столбцов справа и т.д.
Сумма всех чисел в скобках (S1) составит величину А, которую нам нужно будет подставить в формулу для подсчета критерия S. Однако вначале определим максимально возможное значение А, которое мы получили бы, если бы все значения справа были больше значений слева. Эта величина называется величиной В и вычисляется по формуле:
2 Для крайнего правого столбца S, не указываются, поскольку они равны нулю.
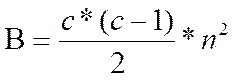
где с - количество столбцов (групп);
n - количество испытуемых в каждом столбце (груапе).
В данном случае:
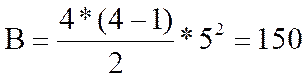
Эмпирическое значение критерия S вычисляется по формуле:
S=2*А- В
где А- сумма всех "превышений" по всем значениям;
В- максимально возможное количество всех "превышений".
В данном случае:
S=-150=-92
По Табл. III Приложения 1 определяем критические значения S для с=4, п=5:
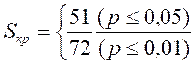
Построим "ось значимости".
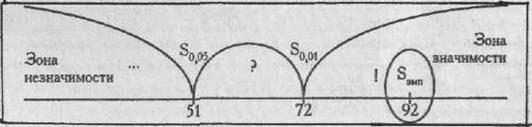
Мы помним, что критерий S построен на подсчете количества превышающих значений. Чем это количество больше, тем более достоверные различия мы сможем констатировать. Поэтому "зона значимости" простирается вправо, в область более высоких значений, а "зона незначимости" - влево, в область более низких значении.
Sэмп > SKP. (р≤0.01)
Ответ: H0 отвергается. Принимается H1. Тенденция повышения значений по шкале Авторитетности при переходе от группы к группе не случайна (р<0,01).
Отвечая на вопрос задачи, мы можем сказать, что группы с разным статусом различаются по показателю Авторитетности, определявшемуся независимо от социометрической процедуры. Критерий S по![]() эволяет указать на тенденцию этих изменений: с ростом статуса растут и показатели по шкале Авторитетности. Однако мы имеем дело здесь, конечно же, не с причинно-следственными связями, а с сопряженными изменениями двух признаков. Возможно, оба они изменяются под влиянием одних и тех же общих факторов, например, последовательно проявляющейся в поведении привычки к лидерству, внушающей способности или "харизмы".
эволяет указать на тенденцию этих изменений: с ростом статуса растут и показатели по шкале Авторитетности. Однако мы имеем дело здесь, конечно же, не с причинно-следственными связями, а с сопряженными изменениями двух признаков. Возможно, оба они изменяются под влиянием одних и тех же общих факторов, например, последовательно проявляющейся в поведении привычки к лидерству, внушающей способности или "харизмы".
Теперь мы можем суммировать все сказанное, алгоритмизировав процесс подсчета критерия S.
АЛГОРИТМ 6
Подсчет критерия S Джонкнра
1.Перенести все показатели испытуемых на индивидуальные карточки.
2.Если количества испытуемых в группах не совпадают, уравнять группы, ориентируясь на количество наблюдений в меньшей из групп. Например, если в меньшей из групп n=3, то из остальных групп необходимо случайным образом
извлечь по три карточки, а остальные отсеять.
Если во всех группах одинаковое количество испытуемых (n≤10), можно сразу переходить к п. 3.
3.Разложить карточки первой группы в порядке возрастания признака и занести полученный ряд значений в крайний слева столбец таблицы, затем проделать то же самое для второй группы и занести полученный ряд значений во второй
слева столбец, и так далее, пока не будут заполнены все столбцы таблицы.
4.Начиная с крайнего левого столбца подсчитать для каждого индивидуального значения количество превышающих его значений во всех столбцах справа (Si).
Полученные суммы записать в скобках рядом с каждым индивидуальным значением.
5.Подсчитать суммы показателей в скобках по столбцам.
6.Подсчитать общую сумму, просуммировав все суммы по столбцам. Эту общую сумму обозначить как А.
7.Подсчитать максимально возможное количество превышающих значений (В), которое мы получили бы, если бы все значения справа были выше значений слева:
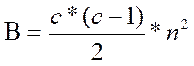
где с - количество столбцов (сопоставляемых групп);
п - количество наблюдений в каждом столбце (группе),
8.Определить эмпирическое значение S по формуле:
S=2*A-B
9.Определить критические значения S по Табл. III Приложения 1 для данного количества групп (с) и количества испытуемых в каждой группе (n).
Если эмпирическое значение S превышает или по крайней мере равняется критическому значению, H0 отвергается.
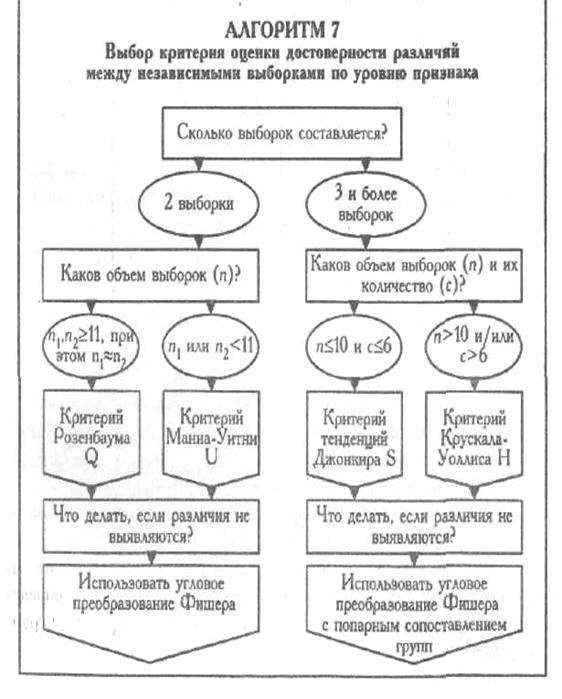
ВНИМАНИЕ! При выборе критерия рекомендуется пользоваться АЛГОРИТМОМ 7.
Алгоритм принятия решения о выборе критерия для сопоставлений
Поможем написать любую работу на аналогичную тему