Назначение метода
Метод дисперсионного анализа для связанных выборок применяется в тех случаях, когда исследуется влияние разных градаций фактора или разных условий на одну и ту же выборку испытуемых.
Градаций фактора должно быть не менее трех.
Непараметрический вариант этого вида анализа - критерий Фридмана χ2r.
Описание метода
В данном случае различия между испытуемыми - возможный самостоятельный источник различий. В схеме однофакторного анализа для несвязанных выборок различия между условиями в то же время отражали различия между испытуемыми. Теперь различия между условиями могут проявиться только вопреки различиям между испытуемыми.
Фактор индивидуальных различий может оказаться более значимым, чем фактор изменения экспериментальных условий. Поэтому нам необходимо учитывать еще одну величину - сумму квадратов сумм индивидуальных значений испытуемых.
Графическое представление метода
На Рис. 7.3 представлена кривая изменения времени решения анаграмм разной длины: четырехбуквенной, пятибуквенной и шестибуквенной. Однофакторный дисперсионный анализ для связанных выборок позволит определить, что перевешивает - тенденция, выраженная этой кривой, или индивидуальные различия, диапазон которых представлен на графике в виде вертикальных линий — от минимального до максимального значения.
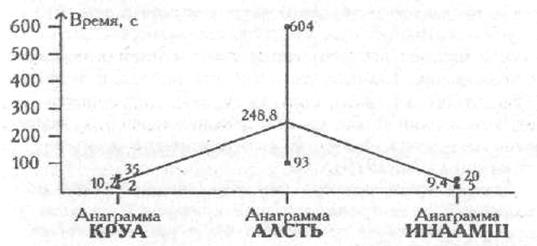
Рис. 7.3. Изменение времени работы над разными анаграммами у тати испытуемых; вертикальными линиями отображены диапазоны изменчивости признака е разных условиях от минимального значения (снизу) до максимального значения (сверху)
Ограничения метода дисперсионного анализа для связанных выборок
1. Дисперсионный анализ для связанных выборок требует не менее трех градаций фактора и не менее двух испытуемых, подвергшихся воздействию каждой из градаций фактора.
2. Должно соблюдаться правило равенства дисперсий в каждой ячейке комплекса. Это условие косвенно выполняется за счет одинакового количества наблюдений в каждой ячейке комплекса. Предлагаемая схема расчета ориентирована только на такие равномерные комплексы.
3. Результативный признак должен быть нормально распределен в исследуемой выборке.
В приводимом ниже примере показатели асимметрии и эксцесса составляют:
А=218
тА=0,632;
tA =2,18/0,632=3,45;
E=4,17;
ME =l,264;
tE =4,17/1,264=3,30.
Таким образом, распределение показателей 5-тй- человек, составляющих дисперсионный комплекс, несколько отличается от нормального: tA>3; tE>3. Однако в целом по выборке распределение нормальное:
n=22;
A=1,26;
тА=0,522
tA=2,41<3;
E=2,29;
mE=1,044;
tE=2,19<3.
По-видимому, необходимо удовлетвориться тем, что в выборке в целом результативный признак распределен нормально. Случайно отобранные 5 человек распределением своих оценок демонстрируют некоторое отклонение. Однако, если бы мы выбирали испытуемых таким образом, чтобы распределение их оценок подчинялось нормальному закону, это нарушило бы правило рандомизации - случайности отбора объектов без учета значений результативного признака при отборе (Плохинский Н.А. 1970).
Данные этого примера нам уже знакомы. Они использовались для иллюстрации непараметрического критерия Фридмана χ2r. Использование здесь этого же примера позволит нам сопоставить результаты, получаемые с помощью непараметрических и параметрических методов.
Пример
Группа из 5 испытуемых была обследована с помощью трех экспериментальных заданий, направленных на изучение интеллектуальной настойчивости (Сидоренко Е. В., 1984). Каждому испытуемому индивидуально предъявлялись последовательно три одинаковые анаграммы: четырехбуквенная, пятибуквенная и шестибуквенная. Можно ли считать, что фактор длины анаграммы влияет на длительность попыток ее решения?
Сформулируем гипотезы.
Наборов гипотез в данном случае два.
Набор А.
Но(А): Различия в длительности попыток решения анаграмм разной длины являются не более выраженными, чем различия, обусловленные случайными причинами.
Н1(А): Различия в длительности попыток решения анаграмм разной длины являются более выраженными, чем различия, обусловленные случайными причинами. Набор Б.
Но(Б): Индивидуальные различия между испытуемыми являются не более выраженными, чем различия, обусловленные случайными причинами.
Н1(Б): Индивидуальные различия между испытуемыми являются более выраженными, чем различия, обусловленные случайными причинами.
Таблица 7.5
Длительность попыток решения анаграмм (сек)
|
Код имени испытуемого |
Условие 1: |
Условие 2. |
Условие 3: |
Суммы го испытуемым |
|
Четырехбуквенная анаграмма |
пятибуквенная анаграмма |
шести буквенная анаграмма |
||
|
1. Л-в |
5 |
235 |
7 |
247 |
|
2. П-о |
7 |
604 |
20 |
631 |
|
3. К-в |
2 |
93 |
5 |
100 |
|
4. Ю-ч |
2 |
171 |
8 |
181 |
|
5. Р-о |
35 |
141 |
7 |
183 |
|
Cvmmы по столбцам |
51 |
1244 |
47 |
1342 |
Установим все промежуточные величины, необходимые для расчета критерия F.
Таблица 7.6
Расчет промежуточных величин для критерия F в примере об анаграммах
|
Обозначение |
Расшифровка обозначения |
Экспериментальное значение |
|
Тс |
суммы индивидуальных значений по каждому из условий (столбцов) |
51; 1244; 47 |
|
∑T2c |
сумма квадратов суммарных значений по каждому из условий |
∑T2c =512+12442+472 |
|
n |
количество испытуемых |
n=5 |
|
c |
количество значений у каждого испытуемого (т. е. количество условий) |
c=5 |
|
N |
общее количество значений |
N=15 |
|
Tи |
суммы индивидуальных значений по каждому испытуемому |
247; 631; 100; 181; 183 |
|
∑T2и |
сумма квадратов сумм индивидуальных значений по испытуемым |
247г+6312+1002+181г+1832 |
|
(∑xi)2 |
квадрат общей суммы индивидуальных значений |
(∑xi)2=13422 |
|
1 *(∑xi)2 N |
константа, которую нужно вычесть из каждой суммы квадратов |
1/N*(∑xi)2 = 1*13422 15 |
|
xi |
каждое индивидуальное значение |
|
|
∑x2i |
сумма квадратов индивидуальных значений |
Мы по-прежнему помним разницу между квадратом суммы и суммой квадратов!
Последовательность расчетов приведена в Табл. 7.7.
Таблица 7.7.
Последовательность операций в однофакторной модели дисперсионного анализа для связанных выборок
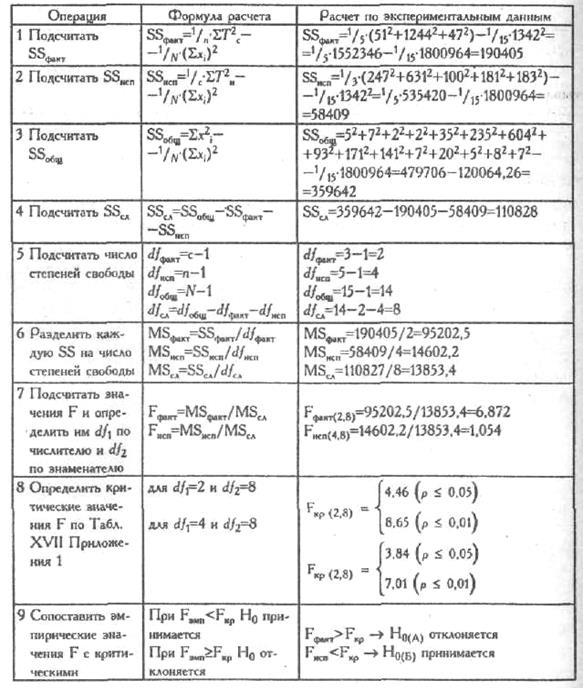 |
Последовательность операций в однофакторной модели
Примечание: (См.Приложение 2).
Вывод:
Но(А) отклоняется. Различия в объеме воспроизведения слов в разных условиях являются более выраженными, чем различия, обусловленные случайными причинами (р<0,05).
Но(Б) принимается: Индивидуальные различия между испытуемыми являются не более выраженными, чем различия, обусловленные случайными причинами.
Однако, судя по Рис. 7.3, мы не можем утверждать, что срабатывает фактор длины анаграммы. Более значимыми оказываются качественные, а не количественные различия между анаграммами. Как мы уже имели возможность убедиться (см. параграфы 3.4 и 3.5), непараметрический L - критерий Пейджа подтверждает тенденцию увеличения индивидуальных показателей при переходе от анаграммы КРУА к анаграмме ИНААМШ, а затем к анаграмме АЛСТЬ (р<0,01). Значимые различия были получены и с помощью критерия Фридмана χ2r
(р=0,0085).
Итак, непараметрические критерии позволяют нам констатировать более высокий уровень значимости различий между условиями!
Зачем же тогда использовать достаточно сложный дисперсионный анализ? Для того, чтобы подобрать существенные факторы, которые могут стать основой для формирования двух-, трех- и более факторных дисперсионных комплексов, позволяющих оценить не только влияние каждого из факторов в отдельности, но и их взаимодействие.
Приложение 1
Таблица 7.4.
Последовательность операций в однофакторном дисперсионном анализе для несвязанных выборок
|
Операция |
Формула расчёта |
Расчёт по экспериментальным данным |
|
1.Подсчитать SSфакт |
|
SSфакт=(432+372+242)/6-1042/18=31,44 |
|
2.Подсчитать SSобщ |
|
SSобщ=82+72+92+52+62+82+72+82+52 +42+62+72 +42+52+32+62+22+42-1042/18=63,11 |
|
3. Подсчитать случайную (остаточную) величину SSсл |
SSсл = SSобщ - SSфакт |
SSсл=63,11-31,44=31,67 |
|
4.Определить число степеней свободы |
dfфакт=с-1 dfобщ=N-1 dfсл = dfобщ –dfфакт |
dfфакт=3-1=2 dfобщ=18-1=17 dfсл = 17-2=15 |
|
5.Разделить каждую SS на соответствующее число степеней свободы |
MSфакт= SSфакт/ dfфакт MSсл =SSсл/ dfсл |
MSфакт= 31,44/2=15,72 MSсл =31,67/15=2,11 |
|
6.Подсчитать значение Fэмп |
Fэмп= MSфакт /MSсл |
Fэмп(2,15)= 15,72/2,11=7,45 |
|
7.Определить критическое значение по Таблице ХУ11 Приложения 1 |
Для df1= 2df2 =15 |
|
|
8.Сопоставить эмпирическое и критическое значение F |
При Fэмп ≥Fкр Н0 отклоняется |
Fэмп >Fкр → Н0 отклоняется |
Приложение 2
Таблица 7.7.
Последовательность операций в однофакторном дисперсионном анализе для связанных выборок
|
Операция |
Формула расчёта |
Расчёт по экспериментальным данным |
|
1.Подсчитать SSфакт |
|
SSфакт= |
|
2.Подсчитать SSисп |
|
SSисп= |
|
3. Подсчитать случайную (остаточную) величину SSобщ |
SSобщ = ∑х2i- |
SSобщ=52 +72 +22+22+35 2+2352 +6042 +932 +1712 +1412 +72 +202 +52 +82 +72 - |
|
4.Подсчитать SSсл |
SSсл =SSобщ -SSфакт -SSисп |
SSсл =359642-190405-58409=110828 |
|
5.Подсчитать число степеней свободы |
dfфакт=с-1 dfисп=n-1 dfобщ = N-1 dfсл =dfобщ -dfфакт dfисп |
dfфакт=3-1=2 dfисп=5-1=4 dfобщ = 15-1=14 dfсл = 14-2-4=8 |
|
6.Разделить каждую SS на число степеней свободы |
MSфакт= SSфакт /dfфакт MSисп = SSисп /dfисп MSсл = SSсл /dfсл |
MSфакт= 190405/2=95202,5 MSисп = 58409/4=14602,2 MSсл = 110827/8=13853,4 |
|
7.Подсчитать значения F и определить им df1 по числителю и df2 по знаменателю |
Fфакт=MSфакт /MSсл Fисп=MSисп /MSсл |
Fфакт(2,8)=95202,5/13853,4=6,872 Fисп(4,8)=14602,2/13853,4=1,054 |
|
8.Определить критические значения F по Табл.ХУ11 Приложения 1 |
Для df1 =2 и df2=8 Для df1 =4 и df2=8 |
|
|
9.Сопоставить эмпирические значения F с критическим |
При Fэмп <Fкр Н0 принимается При Fэмп >Fкр Н0 отклоняется |
Fфакт >Fкр → Н0(А) отклоняется Fфакт <Fкр → Н0(Б) принимается |
Поможем написать любую работу на аналогичную тему