Если в ходе проверки разрабатываемая модель признана значимой, достаточно точной, и ее качество нас устраивает, то на ее основе разрабатывается точечный прогноз. Он получается путем подстановки в модель значений времени t, соответствующих периоду упреждения k (количество шагов прогноза): t=n+k. Так в случае трендовой модели в виде полинома первой степени – линейной модели роста (4) – экстраполяция на k шагов вперед имеет вид:
![]() (2.7)
(2.7)
Для учета случайных колебаний при прогнозировании рассчитываются доверительные интервалы, зависящие от стандартной ошибки (2.6), периода упреждения k, длины временного интервала n и уровня значимости прогноза α. В частности, для прогноза (2.7) будущие значения ![]() с вероятностью (1–α) попадут в интервал:
с вероятностью (1–α) попадут в интервал:
![]() где
где ![]()
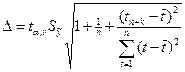 . (2.8)
. (2.8)
В качестве примера рассмотрим разработку трендовой модели и получение прогнозных оценок динамики ВВП России на основе реального временного ряда, представленного в таблице 2.2.
Таблица 2.2
Динамика ВВП России
|
№ |
Дата |
ВВП (млр. руб.) |
|
1 |
1.99 |
238 |
|
2 |
2.99 Внимание!
Если вам нужна помощь в написании работы, то рекомендуем обратиться к
профессионалам. Более 70 000 авторов готовы помочь вам прямо сейчас. Бесплатные
корректировки и доработки. Узнайте стоимость своей работы.
|
249 |
|
3 |
3.99 |
287 |
|
4 |
4.99 |
340 |
|
5 |
5.99 |
342 |
|
6 |
6.99 |
373 |
|
7 |
7.99 |
360 |
|
8 |
8.99 |
380 |
|
9 |
9.99 |
403 |
|
10 |
10.99 |
419.08 |
|
11 |
11.99 |
451 |
|
12 |
12.99 |
460 |
|
13 |
1.00 |
379.8 |
|
14 |
2.00 |
410.7 |
Требуется:
I
1) Определить наличие тренда
- с помощью критерия Фишера при α=5% уровне значимости. Для получения критического значения воспользуйтесь функцией FРАСПОБР(a; n1; n2).
- с помощью критерия Стьюдента при α=5% уровне значимости. Для получения критического значения воспользуйтесь функцией CTЬЮДРАСПРОБР(a; n1 + n2 -2);
2) Построить диаграмму зависимости Y от t, добавить линию тренда (нажать правую кнопку мыши, выделив любую из точек графика), вывести уравнение тренда на диаграмму (в пункте «Параметры тренда» поставить галочку на позиции «Показывать уравнение на диаграмме»);
3) Построить линейную модель Y=a0+a1 t, параметры которой оценить по МНК. Сравнить их со значениями, полученными на диаграмме;
4) Рассчитать модельные (предсказанные) значения ![]() и остатки
и остатки ![]() .
.
5) Оценить адекватность построенной модели на основе исследования:
- Случайности остаточной компоненты по критерию пиков. Подсчитать число поворотных точек р. Если
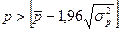 , где
, где 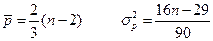 , а квадратные скобки означают целую часть числа, то гипотеза принимается;
, а квадратные скобки означают целую часть числа, то гипотеза принимается; - Независимости уровней ряда остатков по критерию Дарбина-Уотсона (критические значения приведены в Таблице 2) Вычислить значение
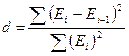 , где Еi – i-тый уровень остаточной последовательности (i=1..9). Если же ситуация оказалась неопределенной, применяют другие критерии. В частности, можно воспользоваться первым коэффициентом автокорреляции:
, где Еi – i-тый уровень остаточной последовательности (i=1..9). Если же ситуация оказалась неопределенной, применяют другие критерии. В частности, можно воспользоваться первым коэффициентом автокорреляции: 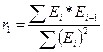 , критический уровень которого rкрит = 0,36;
, критический уровень которого rкрит = 0,36; - Проверить гипотезу о нормальном распределении остаточной последовательности по R/SE – критерию. В нашем случае R = Emax ‑ Emin, а
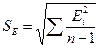 . Критические границы возьмите из Таблицы 3;
. Критические границы возьмите из Таблицы 3; - Проверить гипотезу о равенстве математического ожидания случайной компоненты нулю на основе t ‑ критерия Стьюдента. Расчетное значение этого критерия задается формулой
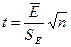 где
где 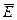 — среднее арифметическое значение уровней остаточной последовательности Ei; SE
— стандартное (среднеквадратическое) отклонение для этой последовательности. Для получения критического значения ta,v
статистики Стьюдента с заданным уровнем значимости a=0,05 и числом степеней свободы v=n-1 воспользуйтесь функцией Excel CTЬЮДРАСПРОБР(a;n-1).
— среднее арифметическое значение уровней остаточной последовательности Ei; SE
— стандартное (среднеквадратическое) отклонение для этой последовательности. Для получения критического значения ta,v
статистики Стьюдента с заданным уровнем значимости a=0,05 и числом степеней свободы v=n-1 воспользуйтесь функцией Excel CTЬЮДРАСПРОБР(a;n-1).
Сделайте вывод об адекватности модели. Модель адекватна, если ВСЕ вышеперечисленные критерии дают положительный ответ.
6) Провести проверку качества модели с помощью коэффициента детерминации 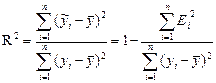 . Он показывает, какую долю вариации исследуемого признака Y описывает наша модель под воздействием изучаемого фактора. Чем ближе к единице R2, тем лучше качество модели.
. Он показывает, какую долю вариации исследуемого признака Y описывает наша модель под воздействием изучаемого фактора. Чем ближе к единице R2, тем лучше качество модели.
7) Для оценки точности модели используйте стандартную ошибку оценки прогнозируемого показателя (или среднеквадратическое отклонение от линии тренда) 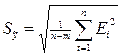 , где n- число опытов, m- число параметров модели (если y=a0+а1t
– модель, то a0 и а1 – параметры), и среднюю относительную ошибку аппроксимации
, где n- число опытов, m- число параметров модели (если y=a0+а1t
– модель, то a0 и а1 – параметры), и среднюю относительную ошибку аппроксимации 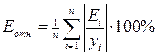 Если ошибка Еотн не превышает 15%, то точность модели считается приемлемой.
Если ошибка Еотн не превышает 15%, то точность модели считается приемлемой.
8) Провести проверку значимости модели с помощью F – теста. Если расчетное значение Fрасч больше критического Fa,n1,n2 при заданном уровне значимости a и со степенями свободы v1=m и v2=n-m (где m –число параметров модели), то модель считается значимой.
![]()
Для получения критического значения воспользуйтесь функцией FРАСПОБР(a; v1,; v2).
9) Построить точечный прогноз на два периода вперед. Он получается путем подстановки в модель значений времени t, соответствующих времени упреждения k: t=n+k. В случае линейной модели экстраполяция на k шагов вперед имеет вид: ![]() n+k=a0+a1*(n+k).
n+k=a0+a1*(n+k).
10) Построить доверительный интервал для прогноза, полученного в предыдущем пункте, с вероятностью P=1-a=1-0,3=0,7=70% и t=СТЬЮДРАСПРОБР(a;n-1):
![]() где
где ![]() .
.
11) Отобразить на графиках фактические данные, результаты расчетов и прогнозирования.
Решение.
1. Определить наличие тренда Y(t).
1.1. С помощью критерия Фишера при α=5% уровне значимости.
Разобьем исходный временной ряд y1, y2, y3, …, yn на две примерно равные по числу уровней части: в первой части n1=7 первых уровней исходного ряда, во второй — n2=6 остальных уровней (n1 + n2 = n).
Для каждой из этих частей вычисляются средние значения и дисперсии:
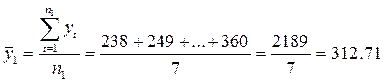 ;
;
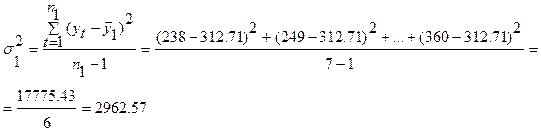 ;
;
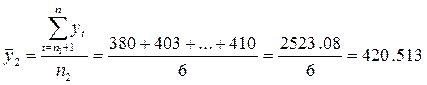 ;
;
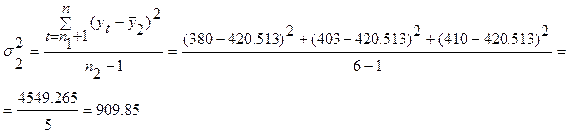
Проверим равенство (однородность) дисперсий обеих частей ряда с помощью F-критерия Фишера расчетное значение этого критерия:
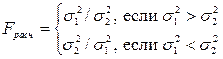
Так как ![]() , то
, то ![]() .
.
Сравним расчетное значение с критическим, полученным с помощью статистической функции Excel Fкрит = FРАСПОБР(a; n1; n2) = FРАСПОБР(0.05;7;6)=4.2. Так как расчетное значение Fрасч меньше критического Fкрит (3.256< 4.2), то гипотеза о равенстве дисперсий принимается. Делается вывод о наличии тренда.
1.2. С помощью критерия Стьюдента при α=5% уровне значимости.
проверяется гипотеза об отсутствии тренда с использованием t-критерия Стыодента. Для этого определяется расчетное значение критерия Стыодента по формуле:
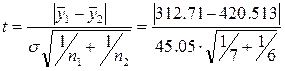
где s — среднеквадратическое отклонение разности средних:
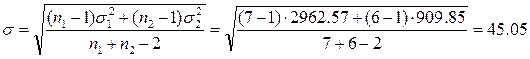 .
.
Для получения критического значения воспользуемся статистической функцией Excel tкрит=CTЬЮДРАСПРОБР(a; n1 + n2 -2)= CTЬЮДРАСПРОБР(0.05; 11)=2.2. Расчетное значение t больше критического значения статистики Стьюдента tкрит (45.05>2.2), значит с вероятностью р=1-a=0,95, гипотеза отвергается, т.е. тренд есть.
В противном случае, если бы t было бы меньше критического, то с заданным уровнем значимости a=0,05 сделали бы вывод о том, что тренда нет.
2. Построить диаграмму зависимости Y от t, добавить линию тренда (нажать правую кнопку мыши, выделив любую из точек графика), вывести уравнение тренда на диаграмму (в пункте «Параметры тренда» поставить галочку на позиции «Показывать уравнение на диаграмме»).
Исходные данные и построенная модель нанесены на график (рис. 2.3)
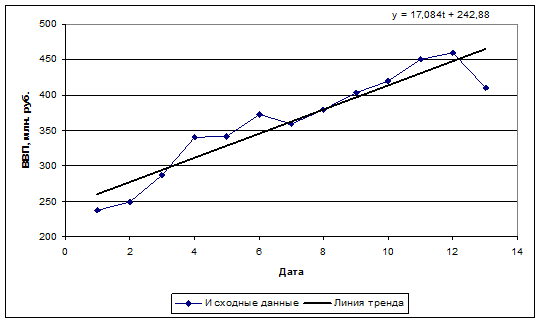
Рис. 2.3. Исходные данные и линия тренда
3. Построить линейную модель Y(t) = а0 + а1t, параметры которой оценить МНК.
Для того чтобы воспользоваться формулами метода наименьших квадратов (2.5), необходимо произвести промежуточные вычисления, которые расположены в таблице 2.3.
Таблица 2.3.
|
|
t |
Y |
Y*t |
t2 |
|
|
1 |
238 |
238 |
1 |
|
|
2 |
249 |
498 |
4 |
|
|
3 |
287 |
861 |
9 |
|
|
4 |
340 |
1360 |
16 |
|
|
5 |
342 |
1710 |
25 |
|
|
6 |
373 |
2238 |
36 |
|
|
7 |
360 |
2520 |
49 |
|
|
8 |
380 |
3040 |
64 |
|
|
9 |
403 |
3627 |
81 |
|
|
10 |
419,08 |
4190,8 |
100 |
|
|
11 |
451 |
4961 |
121 |
|
|
12 |
460 |
5520 |
144 |
|
|
13 |
410 |
5330 |
169 |
|
Сумма |
91 |
4712,08 |
36093,8 |
819 |
|
Среднее |
7 |
362,47 |
2776,45 |
63 |
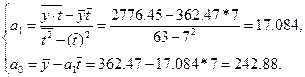
Таким образом, искомая модель принимает вид: ![]() .
.
4. Рассчитать модельные (предсказанные) значения ![]() и остатки
и остатки ![]() .
.
Расчеты приведены в табл. 2.4. В графе 3 приведены расчетные (предсказанные) значения результативного признака (ВВП России), полученные при подстановке фактора t его значений от 1 до 13 в модель ![]() . В графе 4 получены остатки
. В графе 4 получены остатки ![]() вычитанием соответствующих значений элементов графы 3 из графы 2.
вычитанием соответствующих значений элементов графы 3 из графы 2.
5. Оценить адекватность построенной модели. Важным этапом прогнозирования социально-экономических процессов является проверка адекватности (соответствия) модели реальному явлению. Для ее осуществления исследуют ряд остатков ![]() , то есть отклонений расчетных значений от фактических.
, то есть отклонений расчетных значений от фактических.
5.1. Для проверки условия случайности возникновения отдельных отклонений от модели часто используется критерий, основанный на поворотных точках. Уровень последовательности Ei считается максимумом, если он больше двух рядом стоящих уровней, т.е. Ei -1 < Ei > Ei +1 и минимумом, если он меньше обоих соседних уровней, т.е. Ei -1 > Ei < Ei +1. В обоих случаях Ei считается поворотной точкой (в графе 5 они обозначены 1, иначе 0); общее число поворотных точек для остаточной последовательности Ei обозначим через p=8 (сумма графы 5).
В случайной выборке математическое ожидание числа точек поворота p и дисперсия s2p выражаются формулами:
![]()
Критерием случайности с 5%-ным уровнем значимости, т.е. с доверительной вероятностью 95%, является выполнение неравенства ![]() , где квадратные скобки означают целую часть числа. Если неравенство выполняется, то с вероятностью 95% делаем вывод о случайном характере ряда остатков. Если это неравенство не выполняется, модель считается неадекватной. Проверим выполнение неравенства:
, где квадратные скобки означают целую часть числа. Если неравенство выполняется, то с вероятностью 95% делаем вывод о случайном характере ряда остатков. Если это неравенство не выполняется, модель считается неадекватной. Проверим выполнение неравенства:
![]()
Так как р=8>4, то с вероятностью 95% делаем вывод о случайном характере ряда остатков.
Таблица 2.4.
|
t |
yi |
|
Ei=yi- |
пово- ротные точки |
(Ei-Ei-1)2 |
Ei2 |
Ei*Ei-1 |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
1 |
238 |
259,964 |
-21,964 |
- |
- |
482,417 |
- |
|
|
2 |
249 |
277,048 |
-28,048 |
1 |
37,015 |
786,690 |
616,046 |
|
|
3 |
287 |
294,132 |
-7,132 |
0 |
437,479 |
50,865 |
200,038 |
|
|
4 |
340 |
311,216 |
28,784 |
1 |
1289,959 |
828,519 |
-205,287 |
|
|
5 |
342 |
328,3 |
13,7 |
1 |
227,527 |
187,69 |
394,341 |
|
|
6 |
373 |
345,384 |
27,616 |
1 |
193,655 |
762,644 |
378,339 |
|
|
7 |
360 |
362,468 |
-2,468 |
1 |
905,047 |
6,091 |
-68,156 |
|
|
8 |
380 |
379,552 |
0,448 |
0 |
8,503 |
0,201 |
-1,106 |
|
|
9 |
403 |
396,636 |
6,364 |
1 |
34,999 |
40,500 |
2,851 |
|
|
10 |
419,08 |
413,72 |
5,36 |
1 |
1,008 |
28,730 |
34,111 |
|
|
11 |
451 |
430,804 |
20,196 |
1 |
220,107 |
407,878 |
108,251 |
|
|
12 |
460 |
447,888 |
12,112 |
0 |
65,351 |
146,7005 |
244,614 |
|
|
13 |
410 |
464,972 |
-54,972 |
- |
4500,263 |
3021,921 |
-665,821 |
|
|
Сумма |
91 |
4712,08 |
4712,08 |
-0,004 |
8 |
7920,913 |
6750,847 |
1038,221 |
|
Среднее |
7 |
362,47 |
362,47 |
-0,0003 |
5.2. Проверка независимости значений уровней случайной компоненты, т.е. проверка отсутствия существенной автокорреляции в остаточной последовательности может осуществляться по ряду критериев, наиболее распространенным из которых является d-критерий Дарбина—Уотсона. Необходимо вычислить расчетное значение 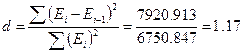 , где Еi – i- тый уровень остаточной последовательности (i=1..13) (расчеты приведены в графах 6 и 7 таблицы 2.4).
, где Еi – i- тый уровень остаточной последовательности (i=1..13) (расчеты приведены в графах 6 и 7 таблицы 2.4).
Критические границы d1=1,08 и d2 =1,36. Так как значение попадает в интервал d1<d<d2 (1.08<1.17<1.36) область неопределенности, значит нет оснований ни принять, ни отвергнуть гипотезу о существовании автокорреляции. Необходимо применять другой критерий. Воспользуемся первым коэффициентом автокорреляции:
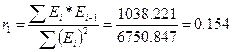 . Сопоставляя это число с табличным значением первого коэффициента автокорреляции 0,485, взятым для уровня значимости α=0,01 и n = 13, увидим, что расчетное значение меньше табличного (0,154<0,485). Это означает, что с ошибкой в 1% ряд остатков можно считать некоррелированным, т. е. свойство взаимной независимости уровней остаточной последовательности подтверждается.
. Сопоставляя это число с табличным значением первого коэффициента автокорреляции 0,485, взятым для уровня значимости α=0,01 и n = 13, увидим, что расчетное значение меньше табличного (0,154<0,485). Это означает, что с ошибкой в 1% ряд остатков можно считать некоррелированным, т. е. свойство взаимной независимости уровней остаточной последовательности подтверждается.
5.3. Проверка гипотезы о нормальном распределении остаточной последовательности по R/SE – критерию. В нашем случае R = Emax ‑ Emin= 28,784 – ( –54,972)=83,756, где Emax и Emin соответственно максимальный и минимальный уровни ряда остатков;
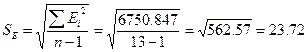 . Получаем расчетное значение критерия
. Получаем расчетное значение критерия ![]() . Для n=13 и α=0,05 найдем критический интервал: . Так как значение R/SE попадает в интервал между критическими границами, то с уровнем значимости 5% гипотеза о том, что остаточная последовательность распределена по нормальному закону, принимается.
. Для n=13 и α=0,05 найдем критический интервал: . Так как значение R/SE попадает в интервал между критическими границами, то с уровнем значимости 5% гипотеза о том, что остаточная последовательность распределена по нормальному закону, принимается.
5.4. Проверка гипотезы о равенстве математического ожидания случайной компоненты нулю на основе t ‑ критерия Стьюдента. Расчетное значение этого критерия задается формулой 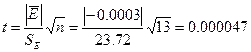 где
где ![]() — среднее арифметическое значение уровней остаточной последовательности Ei (рассчитано в графе 4); SE — стандартное (средне-квадратическое) отклонение для этой последовательности. Для получения критического значения ta,v воспользуемся статистической функцией Excel ta,v = CTЬЮДРАСПРОБР(0,05; 12) = 2,16. Так как расчетное значение t меньше критического значения ta,v
статистики Стьюдента с заданным уровнем значимости a=0,05 и числом степеней свободы v=n-1, то гипотеза о равенстве нулю математического ожидания случайной последовательности принимается.
— среднее арифметическое значение уровней остаточной последовательности Ei (рассчитано в графе 4); SE — стандартное (средне-квадратическое) отклонение для этой последовательности. Для получения критического значения ta,v воспользуемся статистической функцией Excel ta,v = CTЬЮДРАСПРОБР(0,05; 12) = 2,16. Так как расчетное значение t меньше критического значения ta,v
статистики Стьюдента с заданным уровнем значимости a=0,05 и числом степеней свободы v=n-1, то гипотеза о равенстве нулю математического ожидания случайной последовательности принимается.
Так как ВСЕ четыре вышеперечисленные критерии дают положительный ответ, делается вывод о том, что выбранная модель является адекватной реальному ряду экономической динамики.
6. Провести проверку качества модели с помощью коэффициента детерминации
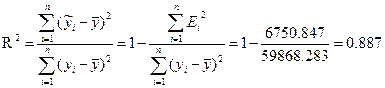 .
.
Расчеты приведены в таблице 2.5. R2 показывает, какую долю вариации исследуемого признака Y описывает наша модель под воздействием изучаемого фактора. Следовательно, 88,7% данных описано нашей моделью.
7. Для оценки точности модели используем стандартную ошибку оценки прогнозируемого показателя (или среднеквадратическое отклонение от линии тренда) 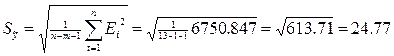 , где n=13 - число опытов, m=1 - число факторов, включенных в модель (это время t), и среднюю относительную ошибку аппроксимации
, где n=13 - число опытов, m=1 - число факторов, включенных в модель (это время t), и среднюю относительную ошибку аппроксимации 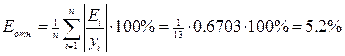 . Так как ошибка Еотн<15%, точность модели считается приемлемой.
. Так как ошибка Еотн<15%, точность модели считается приемлемой.
Таблица 2.5.
|
|
t |
yi |
|
Ei=yi- |
Ei2 |
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
1 |
238 |
259,964 |
-21,964 |
482,417 |
15492,206 |
0,0923 |
36 |
|
|
2 |
249 |
277,048 |
-28,048 |
786,690 |
12874,917 |
0,1126 |
25 |
|
|
3 |
287 |
294,132 |
-7,132 |
50,865 |
5695,373 |
0,0249 |
16 |
|
|
4 |
340 |
311,216 |
28,784 |
828,519 |
504,797 |
0,0847 |
9 |
|
|
5 |
342 |
328,3 |
13,7 |
187,690 |
418,926 |
0,0401 |
4 |
|
|
6 |
373 |
345,384 |
27,616 |
762,643 |
110,930 |
0,0740 |
1 |
|
|
7 |
360 |
362,468 |
-2,468 |
6,091 |
6,090 |
0,0069 |
0 |
|
|
8 |
380 |
379,552 |
0,448 |
0,201 |
307,382 |
0,0012 |
1 |
|
|
9 |
403 |
396,636 |
6,364 |
40,500 |
1642,868 |
0,0158 |
4 |
|
|
10 |
419,08 |
413,72 |
5,36 |
28,730 |
3204,953 |
0,0128 |
9 |
|
|
11 |
451 |
430,804 |
20,196 |
407,878 |
7837,970 |
0,0448 |
16 |
|
|
12 |
460 |
447,888 |
12,112 |
146,701 |
9512,551 |
0,0263 |
25 |
|
|
13 |
410 |
464,972 |
-54,972 |
3021,921 |
2259,320 |
0,1341 |
36 |
|
Сумма |
91 |
4712,08 |
4712,08 |
-0,004 |
6750,847 |
59868,283 |
0,6703 |
182 |
|
Среднее |
7 |
362,47 |
362,47 |
-0,00031 |
0,0516 |
8. Провести проверку значимости модели с помощью F – теста. Необходимо сравнить расчетное значение
![]()
и критическое Fкрит при заданном уровне значимости a=0,05 и со степенями свободы v1=m и v2=n-m-1 (где m – число факторов, включенных в модель). Для получения критического значения воспользуемся статистической функцией Fкрит=FРАСПОБР(a; v1; v2) = FРАСПОБР(0,05; 1; 11) =4,84.
Так как расчетное значение Fрасч =86,345 больше критического Fкрит=4,84, то модель считается значимой.
9. Построим точечный прогноз на два периода вперед (k=2). Он получается путем подстановки в модель значений времени t, соответствующих времени упреждения k=2: t=n+k=13+2=15. В случае линейной модели экстраполяция на k
шагов вперед имеет вид: ![]() n+k=a0+a1*(n+k)=242.88+17.084*15=499.14 (млн. руб.). То есть экстраполяция модели на 2 шага вперед дает прогнозное значение ВВП на март 2000 года, равное 499,14 млн. руб.
n+k=a0+a1*(n+k)=242.88+17.084*15=499.14 (млн. руб.). То есть экстраполяция модели на 2 шага вперед дает прогнозное значение ВВП на март 2000 года, равное 499,14 млн. руб.
10. Построим доверительный интервал для прогноза, полученного в предыдущем пункте, с вероятностью P=1-a=1-0,3=0,7=70% и t=СТЬЮДРАСПРОБР(a;n-1). В этом случае t=СТЬЮДРАСПРОБР(0,3;12)=1,083.
Получим интервальный прогноз:
![]()
![]()
где ![]()
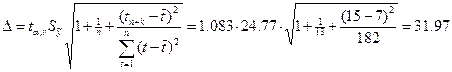 .
.
Таким образом, построенная нами модель является полностью адекватной динамике ВВП и достаточно надежной для краткосрочных прогнозов. Поэтому с вероятностью 70% можно утверждать, что при сохранении сложившихся закономерностей развития значение ВВП, прогнозируемое на март 2000 года с помощью линейной модели роста, попадет в промежуток образованный нижней и верхней границами доверительного интервала ![]() .
.
11. Отобразим на графиках фактические данные, результаты расчетов и прогнозирования (рис. 2.4).
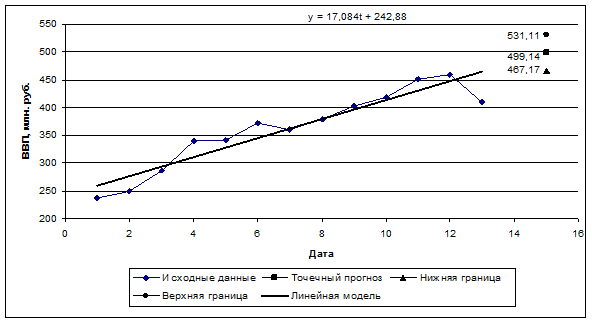
Рис. 2.4. Исходные данные, линейная модель и доверительный интервал для прогноза
Поможем написать любую работу на аналогичную тему