От многомерных probit-моделей отличаются модели множественного выбора. Многомерные probit-модели предполагают принятие нескольких решений, каждое из которых заключается в выборе одного из двух альтернативных вариантов. В моделях множественного выбора нужно принять одно решение, но выбрать между тремя и более вариантами. Часто рассматриваются два возможных типа альтернатив: упорядоченные и неупорядоченные. Например, выбор средств добраться до работы (на машине, на метро, на автобусе и т. д.) – выбор среди неупорядоченных вариантов. Выбор ценных бумаг, исходя из их рейтинга, – выбор среди упорядоченных вариантов.
Рассмотрим сначала модели с неупорядоченными альтернативными вариантами.
В них предполагается, что наблюдаемое значение выбора t-м индивидуумом j-го варианта (уt=j) связывается со значениями факторов, сопутствующих его выбору, эконометрическим уравнением следующего вида:
уt=h(a¢,ztj)+etj, (10.84)
где h – функция, отражающая характер влияния факторов на выбор t-м индивидуумом j-го варианта; etj – ошибка модели; a – вектор параметров модели; ztj – вектор независимых переменных –значений факторов, влияющих на выбор t-го индивидуума, которые могут характеризовать самого индивидуума, альтернативный вариант, либо и то и другое одновременно. Например, при выборе торгового центра для покупки набора товаров вектор ztj может иметь следующую структуру:
ztj =(Kj, Rtj, Dt), (10.85)
где Kj – количество магазинов в j-м торговом центре; Rtj – расстояние от дома t-го индивидуума до j-го торгового центра; Dt – доход t-го индивидуума.
Заметим, что ошибки etj (t=1,2,...,Т) модели (10.84) определяются как et1=1–h(a¢,zt1), et2=2–h(a¢,zt2),..., etJ=J–h(a¢,ztJ).
На основании модели (10.84) могут быть оценены вероятности выбора t-м индивидуумом каждого из альтернативных вариантов, т. е. Р(уt=1), Р(уt=2),..., Р(уt=J). Для этого должны быть известны:
1) функция h(a¢,ztj);
2) закон распределения ошибок etj.
Предположим, что функция h(a¢,ztj) имеет линейный вид:
h(a¢×ztj)=a¢×ztj=![]()
где ![]() – i-я компонента вектора ztj (i=1,...,п).
– i-я компонента вектора ztj (i=1,...,п).
Соответственно ошибки etj (t=1,2,...,Т) модели (10.84) примут следующий вид: et1=1–a¢×zt1, et2=2–a¢×zt2,..., etJ=J–a¢×ztJ.
Предположим, что ошибки etj независимы и распределены по нормальному закону, тогда вероятность выбора t-м индивидуумом j-го варианта определяется следующим образом:
![]() ò
ò![]() ...ò
...ò![]() ò
ò![]() ...
...
ò![]()
где u1,..., uJ – переменные интегрирования, а плотность совместного распределения ошибок jJ (.) определяется как
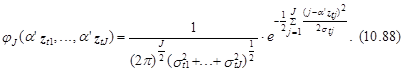
В выражении (10.88) ![]()
Из-за сложности вычисления многомерных интегралов в выражении (10.87) модели, основанные на нормальном распределении ошибок (probit-модели), не нашли широкого применения в исследованиях множественного выбора.
Определение вероятностей выбора Р(уt=1), Р(уt=2),..., Р(уt=J) существенно упрощается, если предположить, что ошибки etj независимы и распределены по закону Вейбулла, т. е. ![]()
Тогда их совместная плотность распределения может быть представлена в следующем виде:
![]()
На основании выражения (10.89) получим, что вероятность выбора выбора t-м индивидуумом j-го варианта определяется как
![]() ò
ò![]() ...ò
...ò![]() ò
ò![]() ...
...
ò![]()
С учетом того, что величина ошибки etj зависит от величины –a¢×ztj, и ![]() в этом случае окончательно имеем:
в этом случае окончательно имеем:
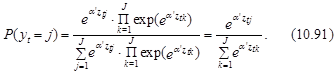
Выражение (10.91) лежит в основе logit-моделей множественного выбора.
Заметим, что при способе формирования независимых факторов, соответствующем выражению (10.85), вероятность выбора t-м индивидуумом j-го варианта будет зависеть от тех факторов, которые отражают характеристики только варианта j (число магазинов в j-м торговом центре) либо совместные характеристики варианта j и индивидуума t (например, расстояние от дома индивидуума до торгового центра является их совместной характеристикой).
Это можно показать следующим образом. Представим вектор ztj в следующем виде: ztj =, где вектор хtj образован факторами, отражающими характеристики варианта j и совместные характеристики варианта j и индивидуума t, а вектор wt – факторами, отражающими исключительно характеристики индивидуума t (например, доход). Вектор параметров a также представим как совокупность двух векторов a=, где a* – вектор коэффициентов, соответствующих независимым переменным хtj, а b – вектор коэффициентов, соответствующих независимым переменным wt. Введя такое представление в модель (10.88), получим следующее выражение, определяющее вероятность выбора t-м индивидуумом j-го варианта:
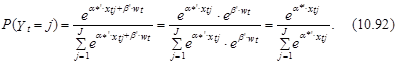
Из выражения (10.92) непосредственно следует, что независимые переменные wt, которые характеризуют индивидуума (но не характеризуют альтернативный вариант), действительно не будут влиять на распределение вероятностей выбора.
Для учета влияния признаков индивидуумов в модели (10.91) необходимо сформировать несколько другую структуру векторов ztj, отличающуюся от структуры, определенной выражением (10.85). Вектора ztj должны выглядеть следующим образом:
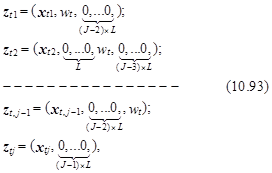
где L – число компонент в векторе wt.
В рассмотренном выше примере, когда индивидуум с доходом Dt выбирает один из трех торговых центров в соответствии с выражением (10.93) вектора ztj примут следующий вид:
zt1=(K1, Rt1, Dt, 0);
zt2=(K2, Rt2, 0, Dt); (10.94)
zt3=(K3, Rt3, 0, 0).
где Kj – число магазинов в j-м торговом центре, Rtj – расстояние от дома t-го индивидуума до j-го торгового центра.
Таким образом, вероятность выбора t-м индивидуумом j-го альтернативного варианта ставится в зависимость и от характеристик варианта и от характеристик индивидуумов. Однако на практике обычно формируются модели, содержащие только какой-либо один набор однородных факторов. Logit-модель, учитывающая влияние на вероятность выбора t-м индивидуумом j-го альтернативного варианта факторов хtj, включающих характеристики варианта j и совместные характеристики варианта j и индивидуума t, называются условной logit-моделью. Заметим, что в условной logit-модели наряду с ранее отмеченными свойствами независимости ошибок и их распределения по закону Вейбулла также предполагается, что ошибки гомоскедастичны.
Для условной logit-модели вероятности Р(уt=j), j=1,...,J также могут быть определены на основе выражения (10.92). Маржинальные эффекты непрерывных независимых переменных х могут быть получены путем дифференцирования вероятностей по факторам х:
![]() =×a *, (10.95)
=×a *, (10.95)
где d=1, если j=k, и d=0 – в противном случае. (Для избежания путаницы в обозначениях индексы наблюдений здесь опущены).
При практическом использовании условной logit-модели часто выясняется, что предположение о независимости ошибок etj не соответствует действительности. Например, при выборе одного из трех торговых центров может оказаться, что количество магазинов в первом из них вдвое больше, чем во втором (K1=2K2), но и расстояние до него вдвое больше, чем до второго (Rt1=2Rt2). Ошибки et1 и et2 в этом случае определяются как
et1=ln1–a12K2–a22Rt2;
et2=ln2–a1K2–a2Rt2. (10.96)
Из выражения (10.96) следует, что ошибки являются зависимыми:
et1=–2(ln2–et2). (10.97)
Зависимость ошибок влечет за собой потерю эффективности оценок параметров a условной logit-модели, полученных при использовании “традиционных” методов оценивания.
Вместе с тем, если рассмотреть несколько другую процедуру выбора t-м индивидуумом альтернативных вариантов, то неэффективность оценок модели можно устранить. В частности, это можно сделать, сформировав последовательную процедуру выбора, на каждом шаге которой выбирается одно из двух возможных решений. Такая процедура может быть описана многомерной probit-моделью, которая может быть представлена в следующем виде:
ytj=a¢×xj+etj
(ytj=1, если индивидуум t выбрал вариант j;
ytj=0 – в противном случае);
~N. (10.98)
где xj – вектор независимых переменных, характеризующих j-й вариант, a – вектор параметров модели; ej – ошибка модели, распределенная по нормальному закону с нулевым средним и ковариационной матрицей S (в общем случае неизвестной).
Рассмотрим следующий пример, отражающий особенности применения данного подхода. Предположим, что изучается выбор одного из трех видов транспорта для поездки на работу (автомобиль, автобус, метро). Введем три бинарные переменные соответствующие каждому средству передвижения: y1=1, если выбран автомобиль, y1=0 для всех остальных видов транспорта; y2=1, если выбран автобус, y2=0 для всех остальных видов транспорта; y3=1, если выбрано метро, y3=0 для всех остальных видов транспорта. Требуется оценить следующий набор вероятностей: P(y1=1); P(y2=1) и P(y3=1).
Выбор одного из трех альтернативных вариантов можно описать в виде “дерева” последовательных решений, в узлах которого происходит бинарный выбор (см. рис 10.3).
![]() автомобиль
автомобиль
|
y1=1
![]()
![]() автобус
автобус
|
y1=0
y2=1
y2=0
метро
Рис.10.3. Последовательность выбора одной из трех альтернатив
В каждом узле, используя бинарные модели, можно оценить условную вероятность выбора соответствующего варианта. Безусловная вероятность его выбора вычисляется по формуле умножения вероятностей. Так, например, безусловная вероятность выбора метро как способа добраться до работы определяется следующим выражением:
P(y3=1)=P(y2=0, y1=0)=P(y2=0)×P(y2=0|y1=0). (10.99)
Вероятность P(y2=0) оценивается с использованием бинарной probit-модели (10.50), вероятность P(y2=0|y1=0) –на основе выражения (10.74)..
Гнездовые logit-модели (nested logit-models).
Как было отмечено, в условной logit-модели ошибки обычно предполагаются гомоскедастичными. Для практики это предположение часто является слишком строгим. Например, в случае выбора одного из трех торговых центров при условии, что количество магазинов в первом из них вдвое больше, чем во втором (K1=2K2), а расстояние до первого вдвое больше, чем до второго (Rt1=2Rt2), дисперсии ошибок e1 и e2 эконометрической модели, связывающей данные выбора первого и второго торгового центра с влияющими на этот выбор факторами (см. выражение (10.96)), определяются следующим образом:
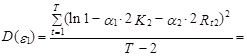
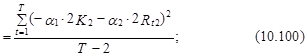
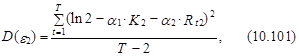
где T – число наблюдений.
Если ![]() , то D(e1)¹D(e2), т. е. ошибки ej гетероскедастичны.
, то D(e1)¹D(e2), т. е. ошибки ej гетероскедастичны.
Один из способов ослабить предположение о гомоскедастичности ошибок в условной logit-модели связан с изменением процедуры выбора альтернативных вариантов. В этом случае варианты разделяются на непересекающиеся группы таким образом, что внутри группы дисперсии ошибок etj уравнения (10.84) являются одинаковыми, а дисперсии ошибок разных групп между собой различаются.
Предположим, что J вариантов могут быть разбиты на L групп, и общий набор вариантов представляется как =, где j|l – j вариант в группе l, Jl – номер последнего варианта в группе l. Используется следующая логика выбора окончательного решения. Сначала выбирается одна из L групп, затем осуществляется выбор варианта в рамках группы. Этот процесс имеет древовидную структуру, которая для двух групп и 5 вариантов может выглядеть следующим образом:
Выбор
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() Группа1 Группа2
Группа1 Группа2
![]()
1|1 2|1 1|2 2|2 3|2
Пусть хj|l – вектор независимых переменных, влияющих на выбор варианта внутри группы, а zl – вектор независимых переменных, влияющих на выбор группы.
Если бы для описания процедуры выбора использовалась условная logit-модель (10.92), то предполагалось бы, что выбор варианта j и выбор группы l не зависят друг от друга.
При условии независимости выбора группы и варианта внутри группы вероятность выбора конкретного варианта определялась бы следующим выражением:
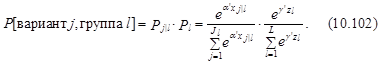
где a и g – вектора параметров.
Для гнездовой logit-модели безусловную вероятность выбора j-го варианта и l-й группы можно представить как произведение условной вероятности выбора j-го варианта при условии, что была выбрана l-я группа, и безусловной вероятности выбора l-й группы.
Заметим, что поскольку внутри группы ошибки гомоскедастичны, то условную вероятность выбора j-го варианта при условии выбора l-й группы, можно определить с использованием выражения (10.92) как

Специфика гнездовой logit-модели, ее отличие от условной logit-модели, состоит в подходе к определению вероятности выбора l-й группы. Для того чтобы раскрыть эту специфику, введем переменную Il, характеризующую “ценность” l-й группы:
![]()
В гнездовой logit-модели “ценность” l-й группы рассматривается как дополнительный фактор, влияющий на выбор этой группы, т. е. вероятность выбора l-й группы определяется следующим образом:
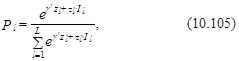
где tl – параметр, который и отличает гнездовую logit-модель от условной logit-модели. В последней он принимает значение 1. Поэтому вероятность выбора l-й группы в условной logit-модели определяется как

В гнездовой logit-модели значение параметра tl оценивается вместе с параметрами g.
В целом, оценивание безусловной вероятности выбора j-го варианта внутри l-й группы в рамках гнездовой модели осуществляется следующим образом:
1. Вектор параметров a оценивается с использованием условной logit-модели типа (10.92), описывающей выбор j-го варианта в зависимости от факторов хj|l. После оценки параметров a по формуле (10.103) определяется ценность l-й группы, т. е. Il.
2. Вектор параметров g и параметр tl также оцениваются с использованием условной logit-модели типа (10.92), которая описывает выбор l-й группы в зависимости от факторов zl и Il.
3. По формулам (10.103), (10.105) оцениваются вероятности Pj|l и Pl. Безусловная вероятность выбора j-го варианта внутри l-й группы определяется как произведение Pj|l и Pl.
Качество оценок, получаемых на основе гнездовой logit-модели, во многом определяется правильностью построения дерева альтернативных вариантов. Отметим, что на практике достаточно трудно оценить, соответствует ли выбранная структура такого дерева исходным условиям модели, состоящих в постулировании определенных допущений относительно дисперсий ошибок (постоянство дисперсий ошибок внутри группы и различие дисперсий в разных группах).
Как это было показано ранее, модификации logit-моделей могут формироваться в зависимости от состава учитываемых в них факторов. В частности, мультиномиальная logit-модель в отличие от рассмотренных выше модификаций учитывает, что на выбор индивидуума t влияют только его характеристики. Примером мультиномиальной logit-модели является модель выбора сферы деятельности (Schmidt and Strauss, 1975). Допустим, что имеется информация: а) относительно возможной сферы деятельности человека: (0) – “прислуга”, (1) – “синий воротничок”, (2) – “ремесленник”, (3) – “белый воротничок”, (4) – “руководитель”; б) относительно характеристик индивидуума (факторов): образование, опыт работы в данной области, пол.
Предположим, что значения зависимой переменной yt и независимых факторов wt, связаны следующим образом:
yt=aj¢×wt +etj, (10.107)
где yt наблюдаемые значения зависимой переменной (т. е. 0, 1,...,J); wt – вектор факторов, содержащий характеристики индивидуума t; aj – вектор параметров, характеризующих влияние факторов wt на выбор конкретного варианта j, etj – ошибка модели.
Предположим также, что ошибки etj, j=1,...,J независимы и распределены по закону Вейбулла, т. е. ![]()
Тогда вероятность выбора t-м индивидуумом j-го варианта может быть представлена в следующем виде (см. выражения (10.89)–(10.91)):
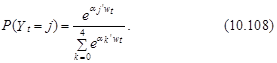
Заметим, что в приведенном примере рассматривается нулевая альтернатива. Это позволяет сократить объем вычислений, поскольку на практике a0 не оценивают, а принимают равным нулевому вектору. Тогда согласно выражению (10.108) вероятности выбора t-м индивидуумом варианта j, j=0,1,..., J–1; определяются согласно следующим формулам:
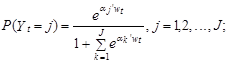
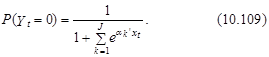
Из выражений (10.109) следует, что логарифм отношения вероятностей выбора j-й и 0-го варианта равен
![]()
![]() aj¢×wt×, (10.110)
aj¢×wt×, (10.110)
а логарифм отношения вероятностей выбора j-го и k-го вариантов –
![]()
![]() wt¢×(aj–ak). (10.111)
wt¢×(aj–ak). (10.111)
Заметим, что, если предположение о независимости ошибок etj не выполняется, то соотношения между вероятностями нуждаются в определенной корректировке.
Модели с упорядоченными альтернативными вариантами.
Варианты в моделях множественного выбора могут быть естественным образом упорядочены. Примерами упорядоченных вариантов являются:
1. Рейтинги ценных бумаг.
2. Результаты дегустации.
3. Опросы общественного мнения.
4. Уровни сложности работ.
5. Типы страховых полисов, выбираемых потребителем (отсутствие такового, частичное покрытие, полное покрытие).
6. Степени занятости (безработный, занят часть дня, занят полный день).
Во всех этих случаях значения зависимой переменной обычно выражают отношения предпочтения среди альтернативных вариантов. Такие отношения могут быть выражены рангами, имеющими вид упорядоченных наборов чисел: 0,1,2,... При этом наиболее предпочтительному варианту может соответствовать как нуль (в этом случае рейтинги вариантов с ростом их ранга уменьшаются), так и последнее число в этой последовательности J (в этом случае рейтинги альтернатив уменьшаются вместе с уменьшением их ранга).
Для анализа определения предпочтительности выбора среди упорядоченных альтернативных вариантов и оценки влияния на этот выбор различных факторов широко применяются порядковые logit- и probit-модели. В таких моделях вероятности предпочтения также, как и в биномиальной probit-модели (10.58), определяются с использованием уравнения латентной регрессии:
yt*=a¢×xt+et. (10.112)
где yt* – ненаблюдаемая переменная, которая по-прежнему представляет собой выгоду (полезность) выбора j-го варианта для t-го индивидуума, например, дивиденды от покупки акций с j-м рейтингом; a – вектор параметров; xt – вектор независимых переменных, влияющих на выбор t-го индивидуума; et – ошибка модели.
Если значение переменной уt* удовлетворяет условию уt*<0, то предполагается, что индивидуум с характеристиками xt, выбирает нулевой альтернативный вариант. Аналогично, если выполняется условие 0<y*£m1, то выбирает первый вариант и т. д. Эту логику выбора можно представить в виде следующей системы:
если yt*£0, то yt=0;
если 0<yt*£m1, то yt=1;
если m1<yt*£m2, то yt=2;
. . . . . . . . . . . . . . . .
если mJ–1£yt*, то yt=J. (10.113)
где mj (j=1,2,...,J–1) – неизвестные параметры, которые подлежат оценке, как и параметры a (и оцениваются теми же методами). Границы m1,..., mJ–1 можно интерпретировать как один из вариантов цензурирования.
Предположим, что ошибки et нормально распределены, e~N* . С учетом этого набор вероятностей появления j-й наблюдаемой переменной (j-го ответа) определяется следующими выражениями:
P(yt=0)=F(–a¢×x t);
P(yt =1)=F(m1–a¢×x t)–F(–a¢×x t);
P(yt =2)= F(m2–a¢×x t)–F(m1–a¢×x t);
. . . . . . . . . . . . . . . . . . . . . . . . . . (10.114)
P(yt =J)=1–F(mJ–1–a¢×x t).
где F(.) – функция закона стандартного нормального распределения.
Из выражений (10.114) следует, что эти вероятности Р(yt =j), j=0,...,J будут положительными, если выполняется следующее условие:
0<m1<m2<... <mJ–1. (10.115)
На рис. 10.4 показано распределение вероятностей выбора конкретных альтернатив.
Рассмотрим особенности определения маржинальных эффектов факторов хt, которые будут характеризовать изменение вероятности выбора j-го альтернативного варианта при изменении одного из независимых факторов на 1 единицу. Допустим, имеется три варианта (этот случай предполагает только один параметр положения m). В соответствии с выражением (10.114) вероятности выбора каждого из вариантов определяются как
P(yt=0)=F(–a¢×xt);
P(yt=1)= F(m–a¢×xt)–F(–a¢×xt);
P(yt=2)=1–F(m–a¢×xt) (10.116)
|
|
|
|
|
|
|
|
|
|
![]()
![]()
![]()
![]()
|
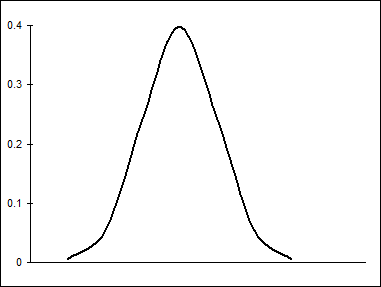
Рис.10.4. Вероятности в упорядоченной probit-модели.
Тогда маржинальные эффекты факторов определяются согласно следующему выражению:
¶P/¶xt=–j(a¢×xt)×a;
¶P/¶xt=×a;
¶P/¶xt=j(m–a¢×xt)×a. (10.117)
где j(.) – функция плотности распределения стандартной нормальной переменной.
На рис. 10.5 сплошной линией изображено распределение yt в зависимости от ошибки et. Рисунок характеризует маржинальный эффект при увеличении одного из факторов хit (i=1,2,..., n) при неизменных a и m. Этот эффект эквивалентен смещению графика распределения вправо, что показано пунктирной линией.
|
|
![]()
![]()
![]()
|
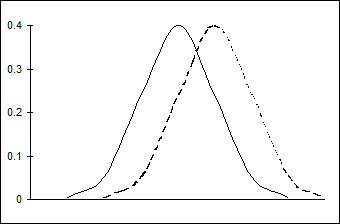
Рис.10.5. Влияние изменения хt на оцененные вероятности.
Согласно первому выражению в (10.117) изменение вероятности выбора 0-го варианта зависит от коэффициента при факторе хi. Если коэффициент ai положителен (для данного набора хt), то вероятность P должна снизиться (производная ¶P/¶хit имеет знак, противоположный знаку ai). Соответственно, если коэффициент ai отрицателен, то вероятность P должна повыситься.
Согласно третьему выражению в (10.117) направление изменения вероятности P при увеличении фактора хi, также определяется знаком коэффициента ai: но в данном случае при положительном ai вероятность увеличивается, при отрицательном ai – уменьшается.
Заметим, что согласно второму выражению в (10.117) изменение вероятности P зависит не только от знака ai, но и от знака, который будет иметь разность двух плотностей . Если эти знаки совпадают, что вероятность P увеличивается с увеличением хit, если не совпадают, то она уменьшается.
Поможем написать любую работу на аналогичную тему