Выявление лучшего варианта эконометрической модели обычно осуществляется путем сравнения соответствующих им качественных характеристик, которые можно рассчитать на основе исходной статистической информации, содержащейся в векторе у, матрице Х, и новой расчетной информации, появляющейся после построении каждого из вариантов модели. Логика в решении этого вопроса достаточно простая: лучшему варианту модели в общем случае должны соответствовать и лучшие значения характеристик его качества.
Здесь следует отметить, что основным условием высокого “качества” модели является обоснованность “математической формы функционала f(a, xt ), как по составу включенных в него независимых переменных, так и по виду их взаимосвязей с зависимой переменной уt, в совокупности определяющих причины ее изменчивости. В этой связи, новая информация, появившаяся после построения функционала f(a, xt), позволяет установить, насколько удалось реализовать это условие на практике.
Отметим основные подходы к оценке “качества” эконометрических моделей.
Ведущая роль при определении характеристик качества эконометрической модели принадлежит ряду ее “выборочной” ошибки еt, t =1, 2,..., Т, который формируется с использованием найденных оценок ее параметров как
![]()
где ![]() – расчетное значение переменной у в момент t, определенное в общем случае как
– расчетное значение переменной у в момент t, определенное в общем случае как ![]() = f (a, xt ) после подстановки в функцию f (a, xt ) значений оценок параметров a0,
a1,..., an и известных значений независимых переменных хit, i=1, 2,..., n, t=1, 2,..., Т. Например, для линейной модели (1.2) значения
= f (a, xt ) после подстановки в функцию f (a, xt ) значений оценок параметров a0,
a1,..., an и известных значений независимых переменных хit, i=1, 2,..., n, t=1, 2,..., Т. Например, для линейной модели (1.2) значения ![]() определяются на основании следующего выражения:
определяются на основании следующего выражения:
![]()
В этой связи отметим, что для каждого набора оценок параметров a0, a1, a2,... того или иного варианта модели, описывающей рассматриваемый процесс, рассчитывается “свой” ряд ошибки et, t=1, 2,..., Т, который можно интерпретировать как ряд оценок ее истинных, но неизвестных значений et (см. (1.1)).
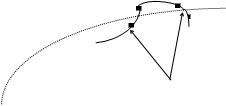
На первый взгляд, соответствие модели свойствам процесса и точность его аппроксимации малоразличимые между собой понятия. Вместе с тем, в их основе лежат различные представления о мерах адекватности модели и процесса. С использованием методов построения многочленов, например, проходящих через заданные точки (задача интерполяции), можно подобрать такое уравнение f(a, xt ), что его значения в точках t=1, 2,..., Т в точности совпадут с наблюдаемыми значениями зависимой переменной уt. Все значения ошибок в этом случае будут равны нулю еt=0, t=1, 2,..., Т. Однако это уравнение практически никогда не будет выражать общую тенденцию развития переменной уt, сформировавшуюся под влиянием независимых факторов хi, i=1, 2,..., n; ни в промежутках между их зафиксированными в моменты t=1, 2,..., Т значениями, ни тем более в прошедшие и будущие периоды времени (см. рис. 1.3). Уравнение f (a, xt ) в этом случае будет выражать тенденцию интерполирующего многочлена, а не реального процесса уt.
Выражая уравнением f (a, xt) общие закономерности процесса уt, практически невозможно добиться совпадения его значений и наблюдаемых уровней зависимой переменной уt в п-мерной точке xt, вследствие того что, как было отмечено ранее, этот функционал не учитывает второстепенные причины изменчивости переменной у, исходная информация не точно отражает рассматриваемые явления и т. п. Однако, если вид функционала f(a, xt) в целом соответствует общим закономерностям изменчивости переменной уt, на интервале t=(1, Т), то можно надеяться, что это соответствие имело место и в прошлом (т. е. при t£0), и на интервалах (t, t+1) и, что более важно, сохранится и в будущем (при t³Т+1). Это является “определенной гарантией” того, что использование функционала f(a, xt) в решении задач управления и прогнозирования процесса уt не приведет к серьезным ошибкам.
уt
![]()
![]() кривая, соответствующая функционалу, опи-
кривая, соответствующая функционалу, опи-
сывающему общую тенденцию переменной уt

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() измеренные значения переменной уt
измеренные значения переменной уt
кривая, соответствующая интерполирующему
функционалу f ( a , xt ),
xt
Рис. 1.3. Различие между интерполирующим и описывающим
общую тенденцию переменной уt вариантами функционала f (a , xt )
Вместе с тем очевидно, что среди нескольких различных вариантов функционала f(a, xt), примерно одинаково отражающих общие тенденции процесса уt, более предпочтительным является тот из них, который обеспечивает и лучшую аппроксимацию (в математическом понимании этого термина).
В общем случае “качество” эконометрической модели оценивается по двум группам характеристик, хотя, как это будет показано далее, предполагаемая группировка не вполне однозначна, поскольку, во-первых, характеристики каждой из групп часто имеют двойное назначение, а, во-вторых, многие из них взаимосвязаны друг с другом. В первую из групп включим показатели, критерии, выражающие “степень” соответствия построенной модели основным закономерностям описываемого ею процесса. Во вторую – показатели и критерии, в большей степени оценивающие точность ее аппроксимации наблюдаемых значений процесса уt .
В этой связи следует отметить, что к критериям первой группы могут быть отнесен и критерий Стьюдента, используемый для оценки значимости влияния каждого из факторов хi, i=1, 2,..., n, на зависимую переменную уt (см. раздел 1.3).
Соответствие эконометрической модели описываемому ею процессу уt в значительной степени может быть установлено на основе анализа свойств рассчитанного ряда ошибки et, t=1, 2,..., Т*. Если вариант модели “верно” отражает основные тенденции процесса уt , то можно ожидать, что значения ошибки в определенной степени случайны, их свойства близки к свойствам процесса “белого шума”. Если же тенденция, закономерности процесса уt учитываются моделью не в полной мере (в модель не включены какие-либо существенные с содержательной точки зрения факторы, выбрана форма функционала f(a, xt), не адекватная характеру взаимосвязей между рассматриваемыми переменными и т. п.), то в ряду ошибки обычно появляется некоторая закономерность, свидетельствующая об утрате свойства ее “случайности”. Заметим, что “неслучайный” характер фактической ошибки модели et может быть предопределен и неверно выбранным методом оценки параметров модели.
Забегая вперед, отметим, что среди методов оценки параметров линейных эконометрических моделей наибольшее распространение получили метод максимального правдоподобия, метод наименьших квадратов и метод моментов. Каждый из них используется при вполне определенных исходных предпосылках относительно свойств ошибки модели et. Например, классические варианты этих методов используются в предположении, что ошибки совпадают со свойствами процесса “белого шума” (нулевое среднее, конечная дисперсия, отсутствие автокорреляционных связей). При этом “метод максимального правдоподобия” предполагает известным закон распределения ошибки. Чаще всего используется предположение о “нормальности” ее распределения. В этой связи построенная с использованием метода максимального правдоподобия модель будет считаться адекватной рассматриваемому процессу, если свойства фактической ошибки et, определенной согласно выражению (1.27), будут не слишком сильно отличаться от предполагаемых свойств ошибки et (“белого шума” с нормальным распределением).
Метод наименьших квадратов не выдвигает столь жестких требований к закону распределения ошибки. Согласно ему оценки параметров моделей определяются исходя из критерия минимума суммы квадратов ошибки. В такой ситуации модель, построенная с использованием данного метода, будет считаться адекватной рассматриваемым процессам, если ее ошибка по своим свойствам идентична “белому шуму”.
Если в отношении ошибки эконометрической модели et выдвигаются предположения, что ее свойства отличны от свойств “белого шума”, то для оценки параметров модели обычно используются так называемые обобщенные модификации данных методов.
Отличие ошибки модели от “белого шума” может выражаться, например, непостоянством ее дисперсии на различных участках интервала t=1, 2,..., Т; наличием взаимосвязи между ее соседними значениями, выражаемыми, например, уравнением следующего вида et =b×et–1+xt, где xt – новая ошибка, по своим свойствам близкая к процессу “белого шума” и т. п.
Однако на практике для моделей многих типов такие свойства ошибки модели априорно предвидеть обычно не представляется возможным. Их можно установить, только анализируя свойства фактической ошибки et, полученной для моделей, оценки коэффициентов которых определены с использованием “классических” методов оценивания.
Таким образом, наличие или отсутствие свойства “случайности” в ряду выборочной ошибки модели et, t =1, 2,..., Т; в определенной мере указывает на “соответствие” или “несоответствие” модели описываемому ею процессу у. В том случае, когда ошибка модели “неслучайна”, может быть рекомендовано уточнить рассматриваемый вариант модели, выбрать более подходящий для данной ситуации метод оценки ее параметров.
Как было отмечено выше, “неслучайность” ошибки может иметь различный характер. Наиболее часто она выражается наличием автокорреляционной связи между соседними ее значениями, тенденциями, характеризующими изменения их квадратов, т. е. тенденциями в ряду et2, t=1, 2,..., Т и других ее производных. Для выявления “неслучайности” в ряду ошибки модели обычно используют специфические тесты, многие из которых будут рассмотрены в последующих главах учебника применительно к моделям соответствующих типов. Здесь же в качестве примера опишем особенности использования для этих целей достаточно универсального теста (критерия) Дарбина-Уотсона. Он наиболее широко применяется в эконометрических исследованиях вследствие своей простоты, хотя и не обладает существенной эффективностью (достоверностью). Тест Дарбина-Уотсона обычно используется для установления факта наличия автокорреляционной зависимости первого порядка в ряду ошибки et, т. е. между соседними ее значениями, et и et+1, t=1, 2,..., Т. Обычно соседние значения ошибки связаны более сильной зависимостью, чем значения et и et+2, et и et+3 и т. д. Вследствие этого отсутствие автокорреляционной связи между рядами значений выборочной ошибки et и et–1, t=1, 2,..., Т–1; позволяет с большой степенью уверенности утверждать, что в ряду истинной ошибки модели et отсутствуют вообще какие-либо автокорреляционные взаимосвязи.
Значение критерия Дарбина-Уотсона рассчитывается по следующей формуле
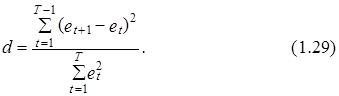
Раскрывая квадрат в числители выражения (1.29), получим:
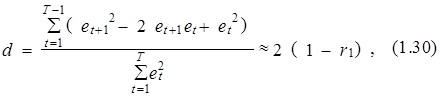
где r1 – коэффициент автокорреляции первого порядка ошибки et, т. е. корреляции между рядами et и et+1.
Из выражения (1.30) непосредственно вытекает, что
0 £ d £ 4. (1.31)
Значение d=0 соответствует случаю, когда между рядами et и et+1 существует строгая положительная линейная зависимость, т. е. r1=+1, и значение d=4 соответствует строгой отрицательной связи, r1 =–1. Если ряды et и et +1 независимы, то r1 =0 и d=2.
Точки d=0; 2; 4 и определяют границы критерия Дарбина-Уотсона, в пределах которых гипотеза о наличии автокорреляции первого порядка в последовательности ошибок либо принимается (в областях близких к 0 или 4), либо отвергается (в области d=2), либо решение по данному критерию остается неопределенным (в промежутках между отмеченными областями). Иными словами, на отрезке выделяются четыре промежуточные точки, таким образом, что 0£d1£d2£2£d3£d4£4. Если расчетное значение критерия Дарбина-Уотсона находится на отрезках , , то гипотеза о наличии автокорреляции первого порядка в ряду ошибок модели принимается, если расчетное значение d находится в интервале , – то отвергается. Значения d, приходящиеся на полуинтервалы и , не позволяют сделать однозначного суждения по данной гипотезе. В последнем случае необходимо проводить более глубокий анализ зависимостей между значениями ошибки et, t=1,2,..., Т.
Другую группу критериев, в большей степени направленных на выявление степени точности аппроксимации функционалом f(a, xt ) наблюдаемых значений зависимой переменной уt, образуют широко используемые в статистике и эконометрике коэффициент множественной корреляции R, коэффициент детерминации D, критерий Фишера F.
Здесь следует отметить, что общепринятой в статистике мерой точности “аппроксимации” является дисперсия (в нашем случае дисперсия модели). Ее значение на практике обычно определяется на основании следующей формулы:
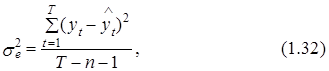
где ![]() =f
(a, xt) – рассчитанные на основании уравнения модели f(a, xt) значения зависимой переменной, Т– количество измерений, п+1 – число параметров модели.
=f
(a, xt) – рассчитанные на основании уравнения модели f(a, xt) значения зависимой переменной, Т– количество измерений, п+1 – число параметров модели.
Однако значение дисперсии не отражает многих существенных аспектов качества модели и, кроме того, оно не очень пригодно для целей содержательного анализа.
Несложно заметить, что величина ошибки тесно связана с уровнем зависимой переменной у, и в этой связи она имеет “абсолютное” содержание. В то же время “точность” в большей степени относительна. Поэтому меньшее значение дисперсии еще не свидетельствует о более высоком “качестве” модели, ее аппроксимирующих возможностях. Большая дисперсия может выражать лишь более высокие уровни независимой переменной, а не ухудшение точности ее аппроксимации построенной моделью.
Здесь следует отметить, что и “относительность” ошибки может рассматриваться в двух аспектах. Во-первых, по отношению к уровню переменной у, а, во-вторых, – к некоторому уже установленному “эталону” точности. Как раз эти аспекты в большей степени и учитывают указанные критерии и коэффициенты.
Коэффициент множественной корреляции показывает степень приближения расчетных (по построенной модели) значений зависимой переменной ![]() (a, xt) к действительным ее значениям уt . Величина коэффициента множественной корреляции меняется в пределах от нуля до единицы (0£ R£1). Значения R, близкие к нулю, свидетельствуют о том, что расчетные значения
(a, xt) к действительным ее значениям уt . Величина коэффициента множественной корреляции меняется в пределах от нуля до единицы (0£ R£1). Значения R, близкие к нулю, свидетельствуют о том, что расчетные значения![]() плохо аппроксимируют значения уt. Если R близок к единице, то это означает, что модель хорошо аппроксимирует исходный ряд значений уt, t=1, 2,..., T.
плохо аппроксимируют значения уt. Если R близок к единице, то это означает, что модель хорошо аппроксимирует исходный ряд значений уt, t=1, 2,..., T.
Значения коэффициента детерминации также находятся на отрезке , 0£D£1. Его конкретная величина показывает долю изменчивости переменной у, объясняемую включенными в модель факторами хi, i=1, 2,..., n. Например, если D=0,81, то это означает, что включенные в модель переменные объясняют 81% изменчивости переменной уt, а остальная ее изменчивость объясняется неучтенными в модели причинами.
Значения коэффициентов множественной корреляции и детерминации рассчитываются на основании следующего выражения*:
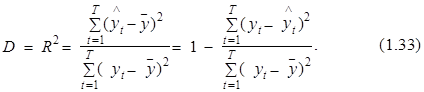
Обоснование целесообразности использования коэффициента детерминации при определении качества построенной эконометрической модели заключается в следующем. “Удачная“ модель должна “объяснять” основные закономерности изменчивости зависимой переменной уt. Количественной мерой этой изменчивости в статистике принято считать показатель, рассчитываемый на основании следующей формулы:
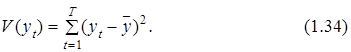
Заметим, что разница ![]() представляет собой отклонение значения уt от среднего уровня этой переменной, а общая изменчивость, таким образом, выражается в виде суммы квадратов всех таких отклонений. После построения модели и определения на ее основании “расчетных” значений
представляет собой отклонение значения уt от среднего уровня этой переменной, а общая изменчивость, таким образом, выражается в виде суммы квадратов всех таких отклонений. После построения модели и определения на ее основании “расчетных” значений ![]() , каждое из таких отклонений можно представить в виде суммы двух составляющих
, каждое из таких отклонений можно представить в виде суммы двух составляющих
![]()
Первое из слагаемых правой части выражения (1.35) представляет собой расчетное значение ошибки модели в момент t, т. е. ![]() . Второе слагаемое выражает отклонение этого расчетного значения от среднего уровня переменной уt. С учетом (1.35) выражение (1.34) можно записать в следующем виде:
. Второе слагаемое выражает отклонение этого расчетного значения от среднего уровня переменной уt. С учетом (1.35) выражение (1.34) можно записать в следующем виде:
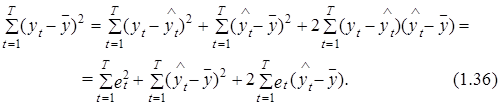
Как будет показано во II главе, ошибка et обладает рядом свойств ![]() , используя которые можно доказать, что последняя сумма в правой части выражения (1.36) равна нулю. Отсюда вытекает, что общая изменчивость переменной уt также может быть представлена в виде двух составляющих
, используя которые можно доказать, что последняя сумма в правой части выражения (1.36) равна нулю. Отсюда вытекает, что общая изменчивость переменной уt также может быть представлена в виде двух составляющих
![]()
При этом первая из них
![]()
выражает сумму квадратов ошибки модели, т. е. часть изменчивости переменной уt, необъясненную построенной моделью, а второе слагаемое ![]() – часть изменчивости переменной уt , которую построенная модель объяснила.
– часть изменчивости переменной уt , которую построенная модель объяснила.
Разделив левую и правую части выражения (1.36) на ![]() , получим
, получим
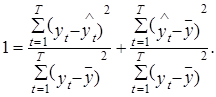
Из последнего выражения непосредственно следует (1.33), т. е.
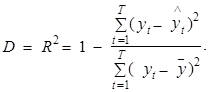
Таким образом, если модель абсолютно точно соответствует исходному ряду зависимой переменной уt, т. е. расчетные значения ![]() f(a, xt) равны уt для всех t =1, 2,..., T, то D=R=1.
f(a, xt) равны уt для всех t =1, 2,..., T, то D=R=1.
В тех случаях, когда модель не может ни в какой мере объяснить изменчивость переменной уt, имеем R=D=0. При линейной форме зависимости f(a, xt) это происходит, например, в тех случаях, когда значения уt равномерно распределяются вокруг линии параллельной оси Х (см. рис. 1.4 (а, б)), что влечет за собой равенство ![]() , t=1, 2,..., T.
, t=1, 2,..., T.
Из изложенного выше следует, что высокие значения переменных D и R ассоциируются с хорошей степенью аппроксимации построенной эконометрической моделью ![]() f(a, xt) исходного (заданного) ряда значений зависимой переменной уt, t=1, 2,..., T, а низкие значения – с плохой аппроксимацией. Вместе с тем следует иметь в виду, что причины плохой аппроксимации могут быть разные. В одних случаях это происходит из-за неверного выбора объясняющих (независимых) переменных, в других – из-за неправильно подобранной формы уравнения модели.
f(a, xt) исходного (заданного) ряда значений зависимой переменной уt, t=1, 2,..., T, а низкие значения – с плохой аппроксимацией. Вместе с тем следует иметь в виду, что причины плохой аппроксимации могут быть разные. В одних случаях это происходит из-за неверного выбора объясняющих (независимых) переменных, в других – из-за неправильно подобранной формы уравнения модели.
|
|
![]()
![]()
![]()
![]() у у
у у
|
![]()
![]() а) б)
а) б)
Рис. 1.4(а,б). Примеры распределения переменной уt , при которых линейная эконометрическая модель )![]() = a0 +
a1 х1t имеет нулевые коэффициенты детерминации и корреляции.
= a0 +
a1 х1t имеет нулевые коэффициенты детерминации и корреляции.
Так, например, если для переменной уt, фактические значения которой обозначены прерывистой линией на рис. 1.4(а) в качестве эконометрической модели использовать уравнение эллипса ![]() а для переменной уt на рис. 1.4(б) – уравнение синусоиды
а для переменной уt на рис. 1.4(б) – уравнение синусоиды ![]() то точность описания рассматриваемых процессов была бы значительно выше и характеристики D и R были бы близкими к единице.
то точность описания рассматриваемых процессов была бы значительно выше и характеристики D и R были бы близкими к единице.
Критерий Фишера (F-критерий) также используется для определения надежности всей модели путем сопоставления ее меры ошибки с величиной меры рассеяния переменной уt относительно ![]() Величина этого критерия определяется по формуле
Величина этого критерия определяется по формуле
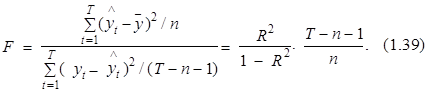
Целесообразность использования критерия Фишера можно обосновать, заменив в выражении (1.39) показатель R2 на его модификацию – скорректированный квадрат коэффициента множественной детерминации ![]() , рассчитываемый с учетом замены суммы квадратов ошибки и изменчивости переменной уt на соответствующие дисперсии. Значение
, рассчитываемый с учетом замены суммы квадратов ошибки и изменчивости переменной уt на соответствующие дисперсии. Значение ![]() рассчитывается согласно следующей формулы:
рассчитывается согласно следующей формулы:
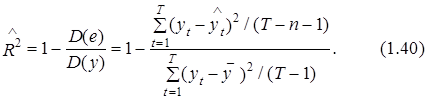
При этом 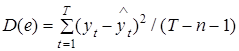 представляет собой дисперсию ошибки et (см. (1.32)), где Т–п–1 – число степеней свободы, учитываемое при ее определении (Т– число измерений, п+1 – количество связанных параметров-коэффициентов модели);
представляет собой дисперсию ошибки et (см. (1.32)), где Т–п–1 – число степеней свободы, учитываемое при ее определении (Т– число измерений, п+1 – количество связанных параметров-коэффициентов модели); 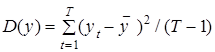 – дисперсия переменной уt, Т–1 – число степеней свободы при одном связанном параметре
– дисперсия переменной уt, Т–1 – число степеней свободы при одном связанном параметре ![]() .
.
На основании (1.33) и (1.40) взаимосвязь между квадратами коэффициентов множественной корреляции R2 и ![]() можно представить в виде следующего соотношения:
можно представить в виде следующего соотношения:
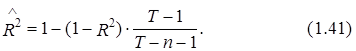
Скорректированный коэффициент ![]() как мера качества построенной модели имеет определенные преимущества по сравнению с его предшественником – коэффициентом R2. В частности, из выражения (1.40) вытекает, что включение в модель независимых факторов, малозначащих с точки зрения объяснения изменчивости переменной уt, может вести к уменьшению значения
как мера качества построенной модели имеет определенные преимущества по сравнению с его предшественником – коэффициентом R2. В частности, из выражения (1.40) вытекает, что включение в модель независимых факторов, малозначащих с точки зрения объяснения изменчивости переменной уt, может вести к уменьшению значения ![]() (см. числитель дробной части (1.40)). В то же время показатель R2 не чувствителен к изменению количества таких переменных.
(см. числитель дробной части (1.40)). В то же время показатель R2 не чувствителен к изменению количества таких переменных.
Здесь необходимо отметить, что критерий Фишера может рассматриваться и в качестве “меры” обоснованности включения в эконометрическую модель всей совокупности независимых переменных. В этом случае его можно отнести и к критериям первой группы, характеризующим степень соответствия построенной модели исследуемому процессу уt.
Критерий Фишера в такой ситуации рассматривается как своего рода тест при проверке гипотезы, что ни один из независимых факторов не играет никакой роли в объяснении изменчивости переменной уt или, что то же самое, все коэффициенты при независимых факторах модели равны нулю (a1=0, a2=0,... , aп =0) (см. раздел (2.2)). В соответствии с этим отношение R2/п в выражении (1.39) представляет собой среднюю долю объясненной изменчивости переменной уt, приходящуюся на один независимый фактор, а (1–R2)/(Т–п–1) – среднюю долю необъясненной изменчивости переменной уt, в расчете на одну степень свободы.
При слабом влиянии независимых факторов на переменную уt (т. е. при ai ®0, i=1,2,..., n) значение R2, как и величина критерия F стремится к нулю, и, наоборот, с увеличением R2 численное значение F также возрастает. Заметим, что показатель F является случайной величиной, представляющей собой отношение двух дисперсий. Эта величина распределена по закону Фишера с п и Т–п–1 степенями свободы (F(п, Т–п–1)). Вследствие этого на практике проверка значимости коэффициентов модели с использованием критерия Фишера состоит в сопоставлении его расчетного значения, определенного для построенного варианта модели по формуле (1.34), с табличным значением F*(п, Т–п–1), соответствующим заданному уровню доверительной вероятности р* (вероятности ошибки первого рода 1–р*) и известным степеням свободы п и Т–п–1.
Если оказывается , что
F<F*(п, Т–п–1),
то гипотезу о незначимости совокупного влияния независимых факторов на переменную уt целесообразно принять (вероятность ее осуществления равна р*). В противном случае роль факторов в объяснении изменчивости переменной уt следует признать существенной. С ростом F эта роль признается все более значимой.
Критерий Фишера можно использовать и при сравнении качества (точности описания исходного процесса уt) двух различных альтернативных вариантов модели. В данном случае его величина рассчитывается по формуле
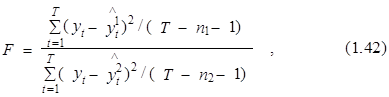
где ![]() =f1(a1, xt1),
=f1(a1, xt1), ![]() =f
2(a2, xt2) – расчетные значения переменной у, полученные на основе первого и второго вариантов моделей соответственно, различающиеся, быть может, формой зависимости f и количеством факторов х; n1 и n2 – количества факторов в первом и втором вариантах соответственно.
=f
2(a2, xt2) – расчетные значения переменной у, полученные на основе первого и второго вариантов моделей соответственно, различающиеся, быть может, формой зависимости f и количеством факторов х; n1 и n2 – количества факторов в первом и втором вариантах соответственно.
Критерий (1.42) является двухсторонним. Особенности его использования состоят в следующем. Если выполняется соотношение
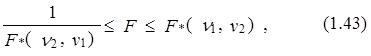
то рассматриваемые альтернативные варианты модели признаются равнозначными с точки зрения точности описания процесса уt.
Если
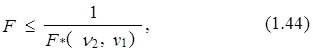
то выбор следует сделать в пользу первого варианта модели, а если
![]()
то – в пользу второго.
F*(n1, n2) – табличное значение критерия Фишера, выбранное для заданного уровня доверительной вероятности р* и числе степеней свободы n1=Т–n1–1 и n2=Т–n2–1.
В заключение данного раздела еще раз обратим внимание на определенные содержательные и количественные взаимосвязи между критериями и показателями качества эконометрической модели различных групп. Например, отметим, что появление автокорреляционных взаимосвязей у значений ошибки, вообще говоря, делает приведенные выше выражения критериев Фишера, коэффициента детерминации, множественных коэффициентов корреляции и т. п. некорректными. Это обусловлено тем, что используемая при расчете их значений сумма квадратов ошибки ![]() не может рассматриваться как “мера точности аппроксимации” заданного ряда значений уt, поскольку не учитывает, например, автокорреляционные связи между разновременными ошибками et и et+i, i=1, 2,...* Критерии Стьюдента и Фишера, коэффициенты детерминации и множественной корреляции, отнесенные к разным группам, часто используются совместно при обосновании выбора варианта эконометрической модели. Это связано с тем, что каждый из включенных в модель факторов, как правило, объясняет некоторую долю изменчивости зависимой переменной уt, пусть даже и небольшую. Вследствие этого, когда независимых факторов не слишком много и между ними не наблюдается сильных взаимосвязей, то исключение из их состава даже малозначимого с точки зрения критерия Стьюдента фактора объективно уменьшает количество информации, объясняющей изменчивость уt. Это, в свою очередь, влечет за собой уменьшение значений характеристик D, R и F. Может возникнуть такая ситуация, когда, удалив на очередном шаге незначимый фактор, исследователь получает менее удачный по этим показателям вариант модели. Если нет других альтернативных ее вариантов, то возникает проблема выбора между “ненадежным” вариантом модели со значимыми факторами и более надежным вариантом, у которого некоторые из независимых переменных незначимы. На практике обычно выбор делается в пользу более “удачной” модели, поскольку более точное описание процесса уt в эконометрике является и более предпочтительным по сравнению с решением задачи установления перечня значимых по степени влияния на переменную уt факторов.
не может рассматриваться как “мера точности аппроксимации” заданного ряда значений уt, поскольку не учитывает, например, автокорреляционные связи между разновременными ошибками et и et+i, i=1, 2,...* Критерии Стьюдента и Фишера, коэффициенты детерминации и множественной корреляции, отнесенные к разным группам, часто используются совместно при обосновании выбора варианта эконометрической модели. Это связано с тем, что каждый из включенных в модель факторов, как правило, объясняет некоторую долю изменчивости зависимой переменной уt, пусть даже и небольшую. Вследствие этого, когда независимых факторов не слишком много и между ними не наблюдается сильных взаимосвязей, то исключение из их состава даже малозначимого с точки зрения критерия Стьюдента фактора объективно уменьшает количество информации, объясняющей изменчивость уt. Это, в свою очередь, влечет за собой уменьшение значений характеристик D, R и F. Может возникнуть такая ситуация, когда, удалив на очередном шаге незначимый фактор, исследователь получает менее удачный по этим показателям вариант модели. Если нет других альтернативных ее вариантов, то возникает проблема выбора между “ненадежным” вариантом модели со значимыми факторами и более надежным вариантом, у которого некоторые из независимых переменных незначимы. На практике обычно выбор делается в пользу более “удачной” модели, поскольку более точное описание процесса уt в эконометрике является и более предпочтительным по сравнению с решением задачи установления перечня значимых по степени влияния на переменную уt факторов.
Таким образом, этапы формирования модели (обоснование формы функционала, состава независимых переменных) и оценки ее качества в значительной степени взаимосвязаны между собой. Для них, как правило, нельзя установить жесткую очередность. Часто информация, полученная на “более поздних этапах” заставляет пересматривать итоги предыдущих. Заметим также, что важную роль на всех этих этапах играет содержательная сторона проблемы. Не подкрепленные результатами содержательного анализа и основанные только на “хороших” количественных критериях варианты эконометрических моделей часто являются с практической точки зрения бесполезными, бессодержательными “аппроксимациями”.
Вместе с тем качество модели в значительной степени зависит от того, насколько “удачны” оценки коэффициентов модели ai , i=0,1,... п. Они играют, пожалуй, основную роль при обосновании ее “качества”, поскольку на основе их значений непосредственно определяется одна из важнейших составляющих модели, характеризующих ее качество, – выборочная ошибка.
Основные подходы к обоснованию “качества” оценок параметров эконометрической модели рассмотрены в следующем параграфе учебника.
Поможем написать любую работу на аналогичную тему