Достаточно широкое распространение при оценке параметров моделей получил и метод максимального правдоподобия, базирующийся на критерии (принципе), согласно которому оптимальные оценки параметров обеспечивают максимум так называемой “функции правдоподобия”. Эта функция может быть интерпретирована как условная плотность совместного распределения j(a|y, х) п+1-го неизвестного параметра модели a0, a1,... an при заданных исходных значениях зависимой переменной yt и независимых факторов хit, i=1,..., п; t=1,..., Т, с учетом того, что эти переменные взаимосвязаны между собой эконометрической моделью с функционалом f(a, x) в общем случае. Оптимальные оценки a0*, a1*,..., an* параметров этого функционала характеризуются в такой ситуации максимальной вероятностью, равной значению функционала правдоподобия в точке (п+1)-мерного пространства оценок с координатами a0*, a1*,..., an*. Такие оценки и называют оценками максимального правдоподобия.
При их нахождении обычно учитывается, что каждому набору значений оценок параметров соответствуют свои собственные ряды расчетных значений зависимой переменной ![]() и фактической ошибки модели еt, это позволяет сформировать функцию правдоподобия на основе плотности совместного распределения значений ошибки модели et в моменты t=1,2,..., Т, и оценки максимального правдоподобия находить, максимизируя эту функцию.
и фактической ошибки модели еt, это позволяет сформировать функцию правдоподобия на основе плотности совместного распределения значений ошибки модели et в моменты t=1,2,..., Т, и оценки максимального правдоподобия находить, максимизируя эту функцию.
В целом, в основе ММП лежат следующие рассуждения.
1. Выбранная модель адекватна процессу изменения (распределению) зависимой переменной yt , в том смысле, что ее форма и состав факторов “правильно” выражают причинно-следственные связи, определяющие его закономерности. Таким образом, истинная ошибка et является ”абсолютно” случайной переменной. Ее закон распределения выражает закон распределения значений yt относительно расчетных значений![]() , рассматриваемых при известных значениях параметров a0, a1,..., an, как выборочные математические ожидания M=
, рассматриваемых при известных значениях параметров a0, a1,..., an, как выборочные математические ожидания M=![]() =a0+a1х1t+...+anхnt . Отклонение значения yt от его математического ожидания объясняется влиянием на этот процесс каких-либо случайных воздействий, которые невозможно учесть в рамках данной модели и т. п.
=a0+a1х1t+...+anхnt . Отклонение значения yt от его математического ожидания объясняется влиянием на этот процесс каких-либо случайных воздействий, которые невозможно учесть в рамках данной модели и т. п.
2. Закон распределения значений yt известен. Чаще всего выдвигается естественное предположение о его нормальном характере. Плотность условного совместного распределения значений yt при известных значениях независимых факторов хit определяется следующим выражением: j (yt хt )~ N (![]() ,
, ![]() ), где
), где ![]() – дисперсия значения yt , определяемая относительно его математического ожидания
– дисперсия значения yt , определяемая относительно его математического ожидания ![]() .
.
Для совокупности случайных величин yt, t=1, 2,..., T этот закон можно выразить путем задания их совместной плотности распределения, в общем случае имеющей следующий вид:
j (y1 ,..., yТ / Х )= N (M, Wy), (2.103)
где M – вектор математических ожиданий наблюдаемых значений y1,..., yТ, Wy – ковариационная матрица значений yt, определяемая следующим выражением:
![]()
Wy = 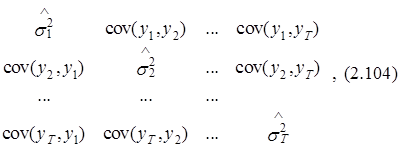
где значения ![]() и
и ![]() следует интерпретировать как дисперсии и ковариации случайных переменных yt и yt и yt+j соответственно*.
следует интерпретировать как дисперсии и ковариации случайных переменных yt и yt и yt+j соответственно*.
В “классическом” варианте ММП в отношении зависимой переменной yt выдвигается предположение о независимости распределений значений yt, рассматриваемых в разные моменты времени t=1, 2,..., T, и о постоянстве их разновременных дисперсий относительно математических ожиданий ![]() .
.
В этом случае матрица Wy имеет следующий вид:
![]()
Wy = ![]() × Е =
× Е = ![]() ×
× 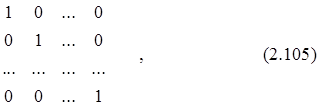
где ![]() – постоянная дисперсия переменных y1,..., yT; Е – единичная матрица Т´Т.
– постоянная дисперсия переменных y1,..., yT; Е – единичная матрица Т´Т.
3. Функция плотности закона распределения ошибки et эквивалентна функции плотности закона распределения переменной yt , т. е. j (et )=j (yt ), и в общем случае j(et )~N(0, We ).
Данное предположение вытекает из того факта, что производные ошибок по соответствующим значениям yt равны 1, т. е. 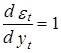 , а производные ошибок по разновременным значениям yt–j равны нулю, j=1,2,..., т. е.
, а производные ошибок по разновременным значениям yt–j равны нулю, j=1,2,..., т. е. 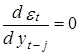 . Это непосредственно устанавливается прямым дифференцированием
. Это непосредственно устанавливается прямым дифференцированием ![]() выражения уt =a0+a1 х1t +...+an хnt +et в предположении, что ei и уj независимы при i¹j. Напомним, что плотность закона совместного распределения значений уt (условного распределения) взаимосвязана с плотностью закона совместного распределения ошибки et, t=1, 2,..., T следующим образом:
выражения уt =a0+a1 х1t +...+an хnt +et в предположении, что ei и уj независимы при i¹j. Напомним, что плотность закона совместного распределения значений уt (условного распределения) взаимосвязана с плотностью закона совместного распределения ошибки et, t=1, 2,..., T следующим образом:
j (y / Х )=j (e)×½¶e/¶y½, (2.106)
где ½¶e/¶y½– якобиан перехода от переменной e к y, рассчитываемый как абсолютное значение следующего определителя:
¶e/¶y = 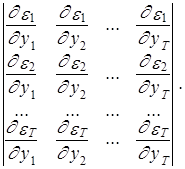
В соответствии с тем, что 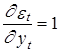 , а
, а 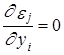 , i¹j, получаем, что ¶e/¶y=1 и j(y
/Х )=j (e).
, i¹j, получаем, что ¶e/¶y=1 и j(y
/Х )=j (e).
Из этого факта вытекает, что соответствующие плотности распределения ошибки e имеют следующий вид:
j (et )~N(0, ![]() );
); ![]() =
= ![]() ;
;
j (e1,..., eT ) = N (0, We), We= Wy, (2.107)
С учетом (2.107) условия независимости разновременных переменных уt и постоянства их дисперсий переходят в соответствующие условия для разновременных значений ошибки et и тогда вместо выражения (2.105) можно записать
Wy=We=se2×Е. (2.108)
Выражение (2.108) c учетом свойства M=0 определяет истинную ошибку модели et как процесс “белого шума”, т. е. как стационарный процесс с постоянным (нулевым) математическим ожиданием (M=уt–M=0), постоянной, независящей от времени дисперсией (![]() =
=![]() ) и нулевыми ковариационными (корреляционными) связями между ее разновременными значениями et и et– 1, et и et–2 и т. д.
) и нулевыми ковариационными (корреляционными) связями между ее разновременными значениями et и et– 1, et и et–2 и т. д.
В основе метода максимального правдоподобия лежит исходное предположение о том, что “лучшим” оценкам a0*, a1*,..., an* “истинных” значений параметров эконометрической модели a0, a1,..., an должен соответствовать наиболее вероятный набор “фактических” значений ошибки е1*, е2*,..., еT*, рассматриваемых как “своего рода оценки” ее истинных значений e1, e2,..., eT и поэтому удовлетворяющих вышеприведенным предположениям.
Таким образом, максимум произведения р(е1)×р(е2)×...×р(еТ) соответствует наиболее вероятному сочетанию значений et, t=1, 2,..., T, обеспечиваемому “наилучшими” оценками параметров модели. При этом имеется в виду, что для произвольного набора значений фактической ошибки е1, е2,..., еT произведение вероятностей р(е1)×р(е2)×...×р(еТ ) в данном случае выражает вероятность совместного распределения их значений, соответствующих определенному набору оценок параметров a0, a1,..., an.
С учетом этого, решение задачи оценки параметров линейной эконометрической модели типа (1.2) может быть получено в результате максимизации целевой функции следующего вида:
![]()
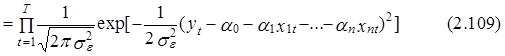
по неизвестным параметрам a0 , a1 ,..., an и se2 при заданных массивах исходных данных, выражаемых вектором известных значений зависимой переменной уt и матрицей значений независимых факторов Х размера Т´(п+1).
![]()
![]() y =
y = ![]() Х =
Х = 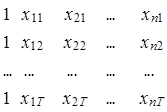 , (2.110)
, (2.110)
в которой столбец, состоящий из единиц, соответствует коэффициенту модели a0.
Поможем написать любую работу на аналогичную тему